[ad_1]
Training robots to perform various manipulation behaviors has been made possible by imitation learning from human demonstrations. One popular method involves having human operators teleoperate with robot arms through various control interfaces, producing multiple demonstrations of robots performing different manipulation tasks, and then using the data to train the robots to perform these tasks independently. More recent efforts have attempted to scale this paradigm by gathering more data with a larger group of human operators over a wider range of functions. These works have demonstrated that imitation learning on large, diverse datasets can yield impressive performance, allowing robots to generalize toward new objects and unseen tasks.
This implies that gathering substantial and rich datasets is a crucial first step in creating broadly proficient robots. But this achievement is only possible with expensive and time-consuming human work. Look at a robot mimic case study where the agent’s job is to move a coke can from one bin to another. Although there is just one scene, one item, and one robot in this straightforward job, a sizable dataset of 200 demos was needed to attain a respectable success rate of 73.3%. Larger datasets, including tens of thousands of demos, have been required for recent attempts to expand to settings with various sceneries and items. For instance, it shows that challenges with minor changes in objects and goals may be generalized using a dataset of over 20,000 trajectories.
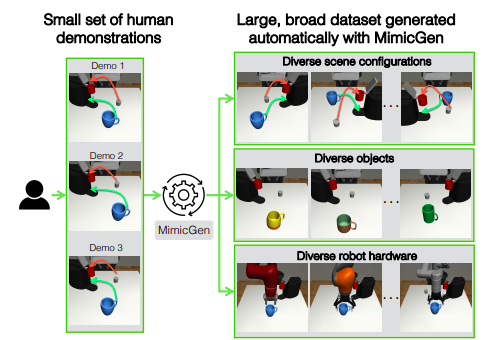
Figure 1: Researchers provide a data production system that, by repurposing human demonstrations to make them useful in new contexts, can generate vast, diversified datasets from a small number of human demos. They use MimicGen to provide data for a variety of items, robot gear, and scene setups.
Several human operators, months, kitchens, and robotic arms are all involved in the roughly 1.5-year data-collecting effort from RT-1 to create rules that can successfully rearrange, clean, and recover things in a few kitchens with a 97% success rate. However, the number of years required to gather enough data to implement such a system in real-world kitchens still needs to be discovered. They ask, “To what extent does this data comprise distinct manipulation behaviors?” These datasets may include comparable alteration techniques used in various settings or circumstances. When grasping a cup, for instance, human operators may exhibit very comparable robot trajectories independent of the mug’s placement on a countertop.
Adapting these trajectories to various situations can help produce a variety of. Although promising, the application of these approaches is limited due to their assumptions regarding certain tasks and algorithms. Rather, they want to create a universal system that can be easily included in current imitation learning processes and enhance various activities’ performance. In this research, they offer a unique data-gathering technique that automatically generates massive datasets across many scenarios using a small selection of human examples. Their technique, MimicGen, splits up a limited number of human demonstrations into pieces focused on objects.
It then chooses one of the human demonstrations, spatially alters each object-centric part, stitches them together, and directs the robot to follow this new route to gather a recent demonstration in a new scenario with varied object postures. Despite being straightforward, they discovered that this technique is quite good at producing sizable datasets from various scenarios. The datasets may be used to imitate learning to train competent agents.
Their contributions include the following:
• Researchers from NVIDIA and UT Austin present MimicGen, a technology that uses new situation adaptation to create vast, diversified datasets from a limited number of human demos.
• They show that MimicGen can provide high-quality data across various scene configurations, object instances, and robot arms—all of which are not included in the original demos—to train skilled agents through imitation learning (see Fig. 1). Pick-and-place, insertion, and interfacing with articulated objects are just a few examples of the many long-horizon and high-precision activities that MimicGen is extensively suited to and that call for distinct manipulation abilities. Using only 200 source human demos, they produced 50K+ additional demonstrations for 18 jobs spanning two simulators and a real robot arm.
• Their method performs comparably to the alternative of gathering more human demonstrations; this raises significant concerns about when it is necessary to request additional data from a human. Using MimicGen to generate an equal amount of synthetic data (e.g., 200 demos generated from 10 human vs. 200 human demos) results in comparable agent performance.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
[ad_2]
Source link