[ad_1]

Image by Author
Ever wonder how people generate such hyper-realistic faces using AI image generation while your own attempts end up full of glitches and artifacts that make them look obviously fake? You’ve tried tweaking the prompt and settings but still can’t seem to match the quality you see others producing. What are you doing wrong?
In this blog post, I’ll walk you through 3 key techniques to start generating hyper-realistic human faces using Stable Diffusion. First, we’ll cover the fundamentals of prompt engineering to help you generate images using the base model. Next, we’ll explore how upgrading to the Stable Diffusion XL model can significantly improve image quality through greater parameters and training. Finally, I’ll introduce you to a custom model fine-tuned specifically for generating high-quality portraits.
First, we will learn to write positive and negative prompts to generate realistic faces. We will be using the Stable Diffusion version 2.1 demo available on Hugging Face Spaces. It is free, and you can start without setting up anything.
Link: hf.co/spaces/stabilityai/stable-diffusion
When creating a positive prompt, ensure to include all the necessary details and style of the image. In this case, we want to generate an image of a young woman walking on the street. We will be using a generic negative prompt, but you can add additional keywords to avoid any repetitive mistakes in the image.
Positive prompt: “A young woman in her mid-20s, Walking on the streets, Looking directly at the camera, Confident and friendly expression, Casually dressed in modern, stylish attire, Urban street scene background, Bright, sunny day lighting, Vibrant colors”
Negative prompt: “disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w, cartoon, painting, illustration, worst quality, low quality”
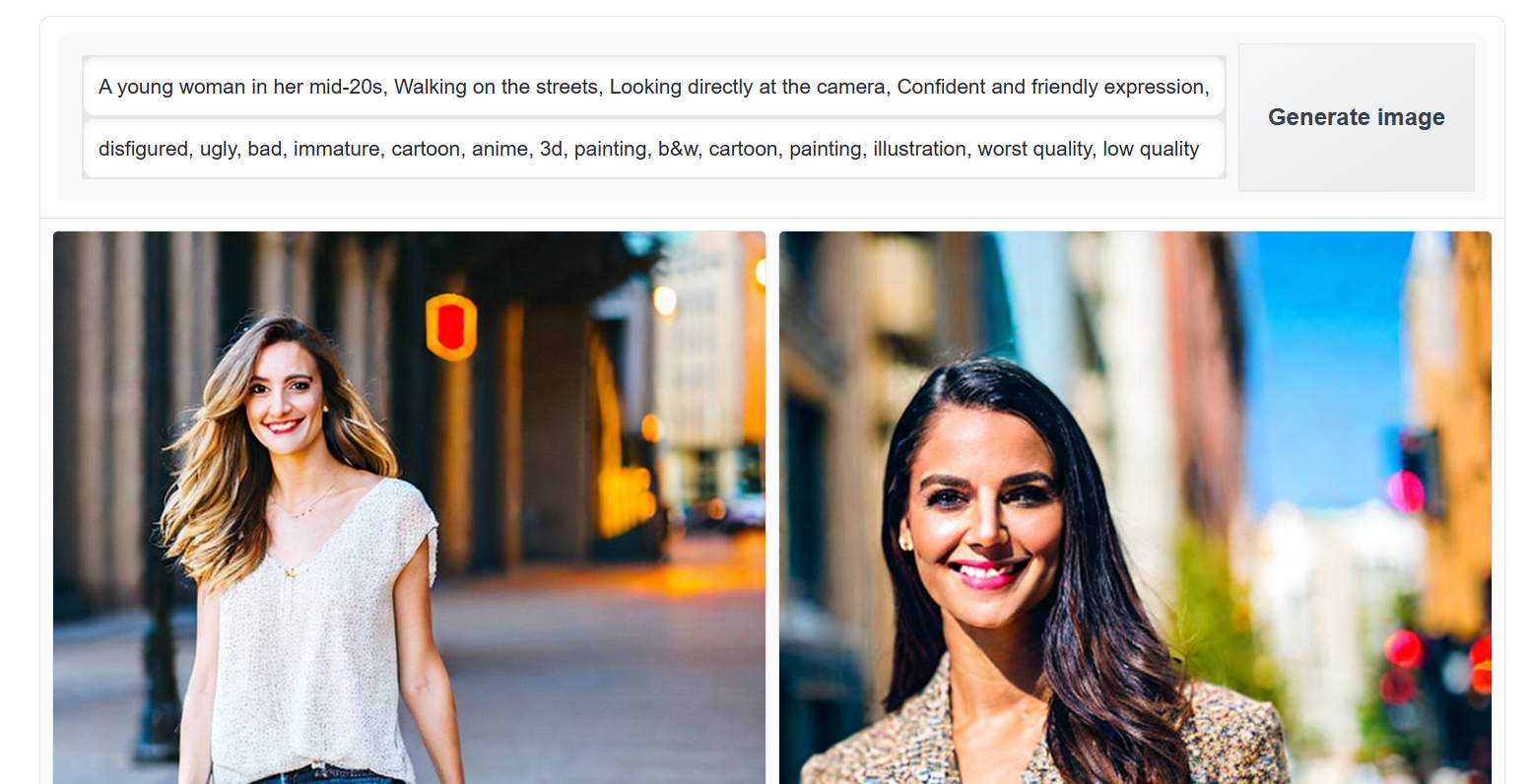
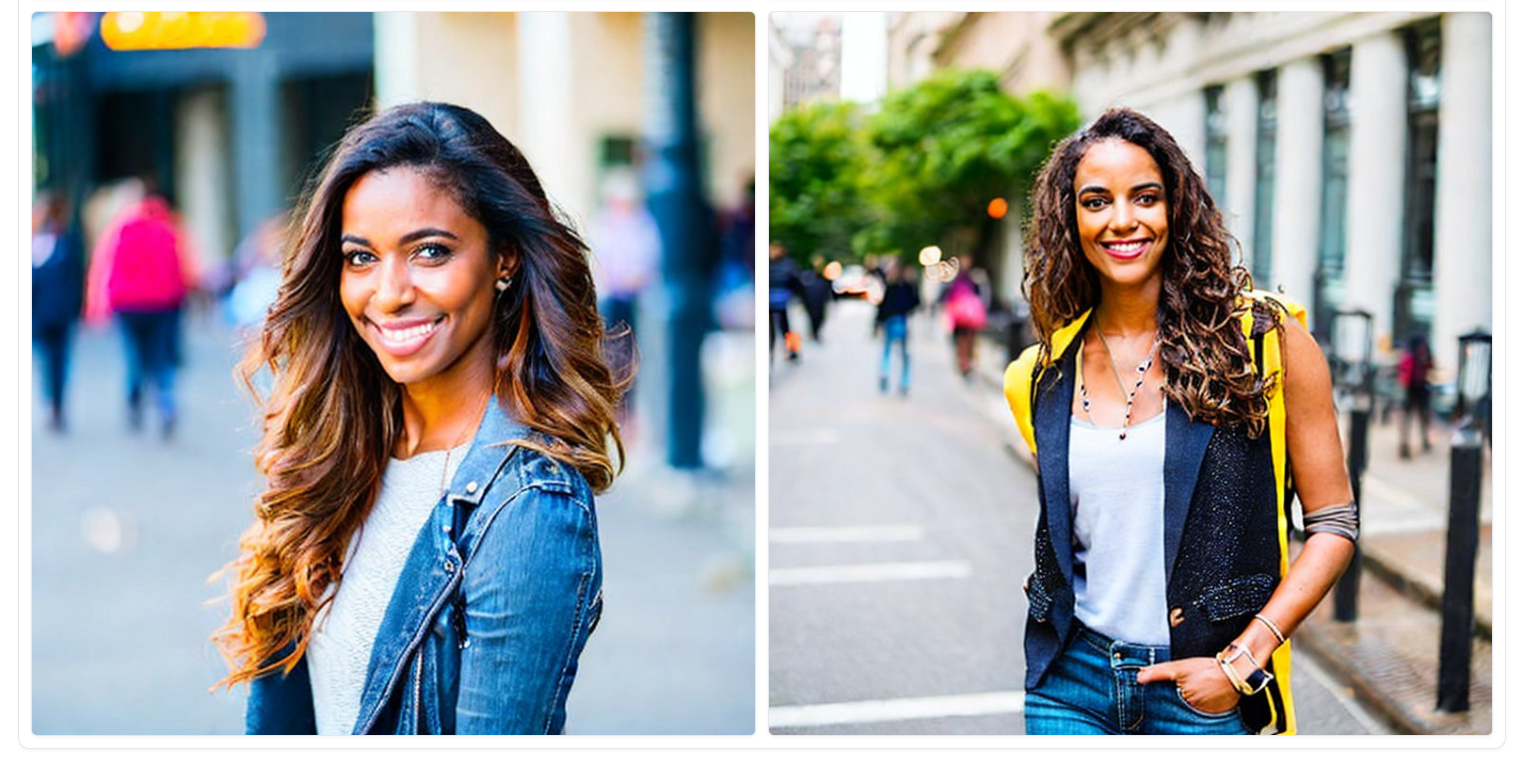
We got a good start. The images are accurate, but the quality of the images could be better. You can play around with the prompts, but this is the best you will get out of the base model.
We will be using the Stable Diffusion XL (SDXL) model to generate high-quality images. It achieves this by generating the latent using the base mode and then processing it using a refiner to generate detailed and accurate images.
Link: hf.co/spaces/hysts/SD-XL
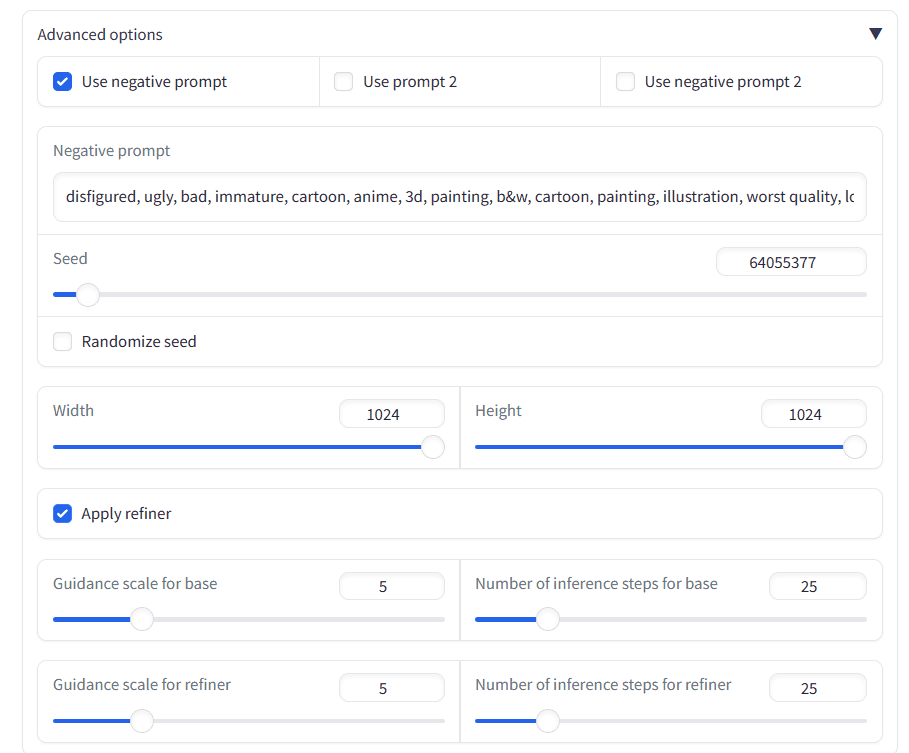
Before we generate the images, we will scroll down and open the “Advanced options.” We will add a negative prompt, set seed, and apply refiner for the best image quality.
Then, we will write the same prompt as before with the minor change. Instead of a generic young woman, we will generate the image of a young Indian woman.

This is a much improved outcome. The facial features are perfect. Let’s attempt to generate other ethnicities to check for bias and compare the results.

We got realistic faces, but all the images have Instagram filters. Usually, skins are not smoother in real life. It has acne, marks, freckles, and lines.
In this part, we will generate detailed faces with marks and realistic skin. For that, we will use the custom model from CivitAI (RealVisXL V2.0) that was fine-tuned for high-quality portraits.
Link: civitai.com/models/139562/realvisxl-v20
You can either use the model online by clicking on the “Create” button or download it to use locally using Stable Diffusion WebUI.
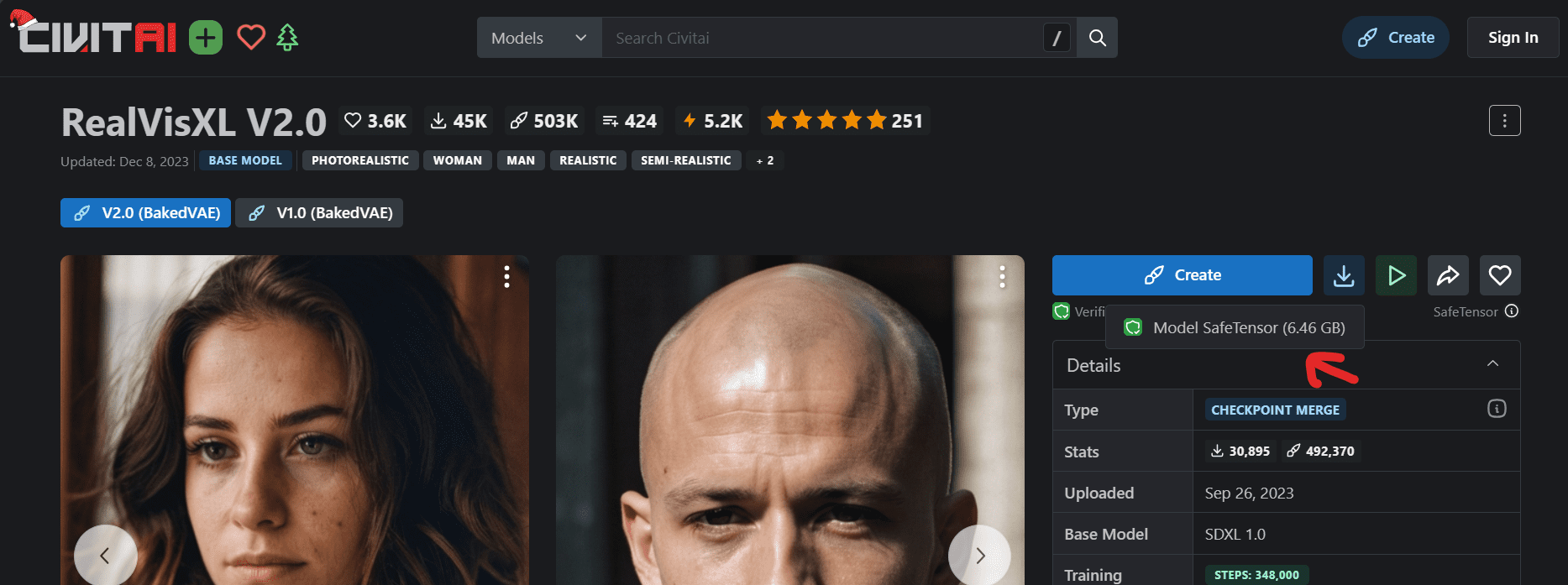
First, download the model and move the file to the Stable Diffusion WebUI model directory: C:\WebUI\webui\models\Stable-diffusion.
To display the model on the WebUI you have to press the refresh button and then select the “realvisxl20…” model checkpoint.
We will start by writing the same positive and negative prompts and generate a high-quality 1024X1024 image.
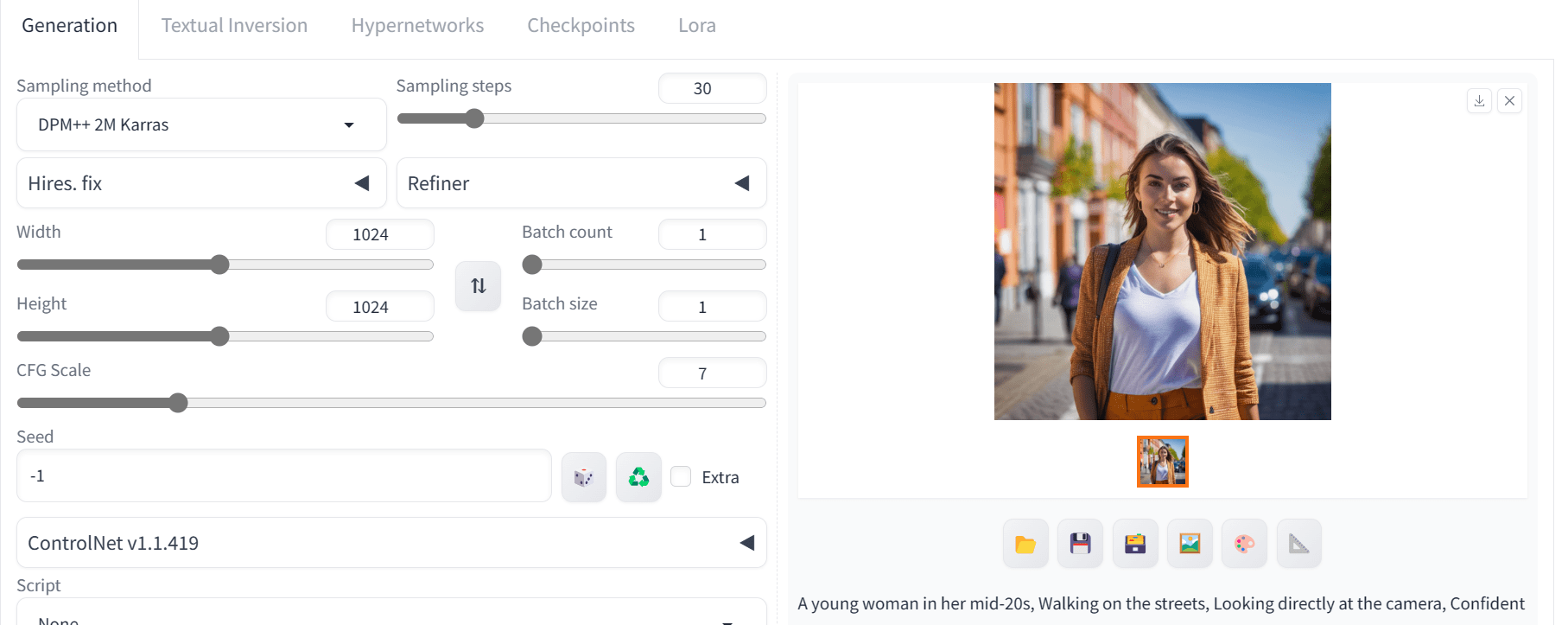
The image looks perfect. To take full advantage of the custom model we have to change our prompt.

The new positive and negative prompts can be obtained by scrolling down the model page and clicking on the realistic image you like. The images on the CivitAI come with positive and negative prompts and advanced steering.
Positive prompt: “An image of an Indian young woman, focused, decisive, surreal, dynamic pose, ultra highres, sharpness texture, High detail RAW Photo, detailed face, shallow depth of field, sharp eyes, (realistic skin texture:1.2), light skin, dslr, film grain”
Negative prompt: “(worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), open mouth”
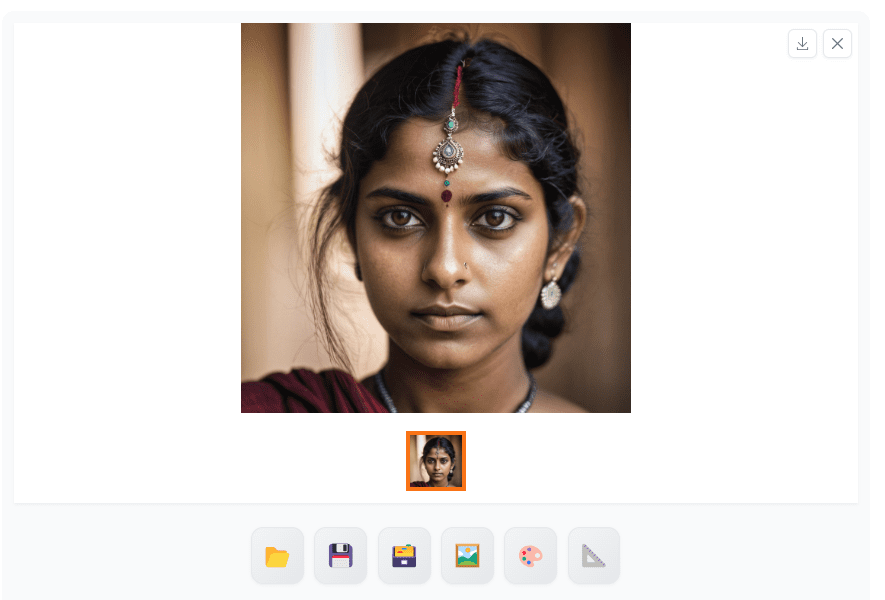
We have a detailed image of an Indian woman with realistic skin. It is an improved version compared to the base SDXL model.
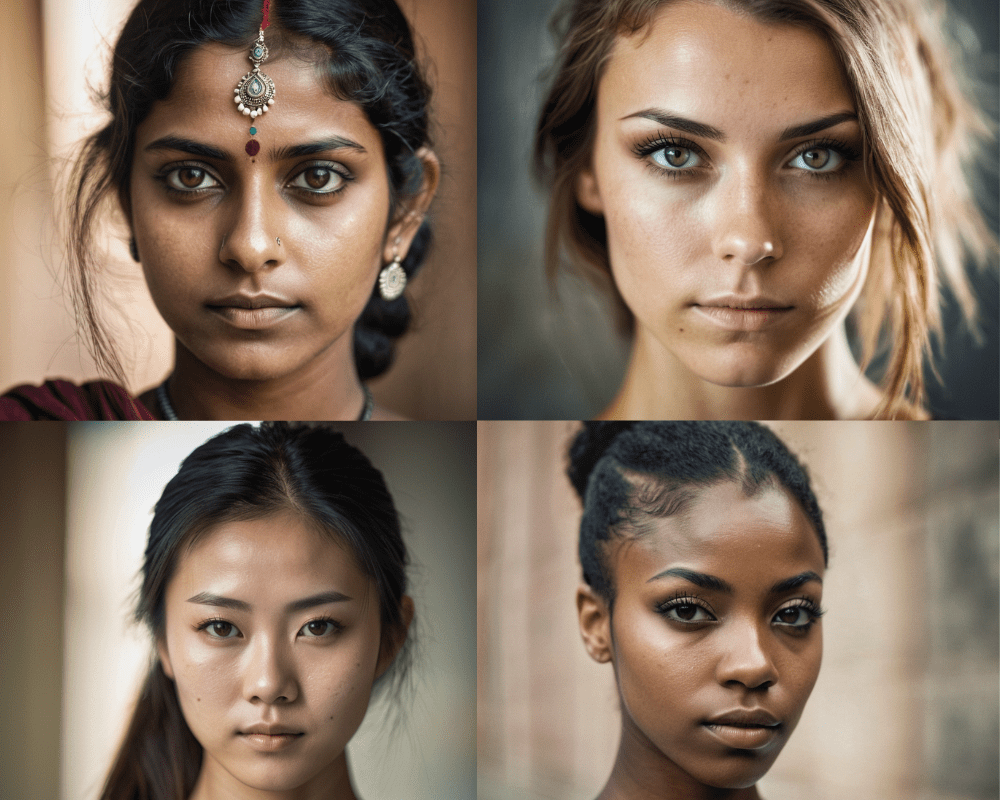
We have generated three more images to compare different ethnicities. The results are phenomenal, containing skin marks, porous skin, and accurate features.
The advancement in generative art will soon reach a level where we will have difficulty differentiating between real and synthetic images. This signals a sustainable future where anyone can create highly realistic media from simple text prompts by leveraging custom models trained on diverse real-world data. The rapid progress implies exciting potential – perhaps one day, generating a photorealistic video replicating your own likeness and speech patterns may be as simple as typing out a descriptive prompt.
In this post, we have learned about prompt engineering, advanced Stable design models, and costume fine tuned models for generating highly accurate and realistic faces. If you want even better results, I will suggest you explore various high quality models available on civitai.com.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in Technology Management and a bachelor’s degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
[ad_2]
Source link