[ad_1]
Object perception in images and videos unleashes the power of machines to decipher the visual world. Like virtual sleuths, computer vision systems scour pixels, recognizing, tracking, and understanding the myriad objects that paint the canvas of digital experiences. This technological prowess, fueled by deep learning magic, opens doors to transformative applications – from self-driving cars navigating urban landscapes to virtual assistants adding more intelligence to visual encounters.
Researchers from Huazhong University of Science and Technology, ByteDance Inc., and Johns Hopkins University introduce GLEE, a versatile model for object perception in images and videos. GLEE excels at locating and identifying objects, demonstrating superior generalization across diverse tasks without task-specific adaptation. Its adaptability extends to integrating Large Language Models, offering universal object-level information for multi-modal studies. The model’s capability to acquire knowledge from various data sources enhances its effectiveness in handling different object perception tasks with improved efficiency.
GLEE integrates an image encoder, text encoder, and visual prompter for multi-modal input processing and generalized object representation prediction. Trained on diverse datasets like Objects365, COCO, and Visual Genome, GLEE employs a unified framework for detecting, segmenting, tracking, grounding, and identifying objects in open-world scenarios. Based on MaskDINO with a dynamic class head, the object decoder uses similarity computation for prediction. After pretraining on object detection and instance segmentation, joint training results in state-of-the-art performance across various downstream image and video tasks.
GLEE demonstrates remarkable versatility and enhanced generalization, effectively addressing diverse downstream tasks without task-specific adaptation. It excels in various image and video tasks, such as object detection, instance segmentation, grounding, multi-target tracking, video instance segmentation, video object segmentation, and interactive segmentation and tracking. GLEE maintains state-of-the-art performance when integrated into other models, showcasing its representations’ versatility and effectiveness. The model’s zero-shot generalization is further improved by incorporating large volumes of automatically labeled data. Also, GLEE serves as a foundational model.
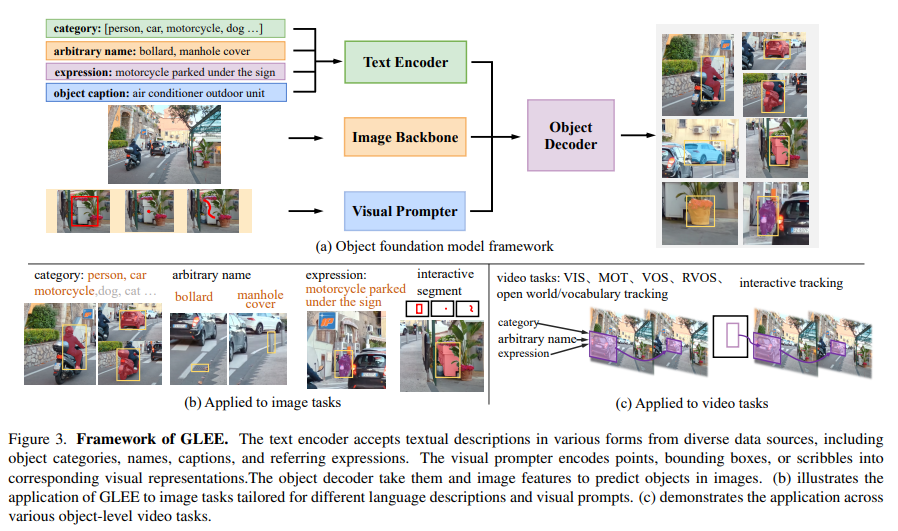
GLEE is a groundbreaking general object foundation model that overcomes limitations in current visual foundation models, providing accurate and universal object-level information. It tackles diverse object-centric tasks adeptly, showcasing remarkable versatility and superior generalization, particularly excelling in zero-shot transfer scenarios. GLEE incorporates varied data sources for general object representations, enabling scalable dataset expansion and enhanced zero-shot capabilities. With unified support for multi-source data, the model accommodates additional annotations, achieving state-of-the-art performance across various downstream tasks, surpassing existing models, even in zero-shot scenarios.
The scope of the research conducted so far and the direction for future research can be focused on the following:
- Ongoing research is being conducted to expand the capabilities of GLEE in handling complex scenarios and challenging datasets, especially those with long-tail distributions, to improve its adaptability.
- Integrating specialized models aims to leverage GLEE’s universal object-level representations, which can enhance its performance in multi-modal tasks.
- Researchers are also exploring GLEE’s potential for generating detailed image content based on textual instructions, similar to models like DALL-E, by training it on extensive image-caption pairs.
- They enhance GLEE’s object-level information by incorporating semantic context, which can broaden its application in object-level tasks.
- Further development of interactive segmentation and tracking capabilities includes exploring varied visual prompts and refining object segmentation skills.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
[ad_2]
Source link