[ad_1]
In the realm of video generation, diffusion models have showcased remarkable advancements. However, a lingering challenge persists—the unsatisfactory temporal consistency and unnatural dynamics in inference results. The study explores the intricacies of noise initialization in video diffusion models, uncovering a crucial training-inference gap.
The study addresses challenges in diffusion-based video generation, identifying a training-inference gap in noise initialization that hinders temporal consistency and natural dynamics in existing models. It reveals intrinsic differences in spatial-temporal frequency distribution between the training and inference phases. Researchers S-Lab and Nanyang Technological University introduced FreeInit, a concise inference sampling strategy; it iteratively refines low-frequency components of initial noise during inference, effectively bridging the initialization gap.
The study explores three categories of video generation models—GAN-based, transformer-based, and diffusion-based—emphasizing the progress of diffusion models in text-to-image and text-to-video generation. Focusing on diffusion-based methods like VideoCrafter, AnimateDiff, and ModelScope reveals an implicit training-inference gap in noise initialization, impacting inference quality.
Diffusion models, successful in text-to-image generation, extend to text-to-video with pretrained image models and temporal layers. Despite this, a training inference gap in noise initialization hampers performance. FreeInit addresses this gap without extra training, enhancing temporal consistency and refining visual appearance in generated frames. Evaluated on public text-to-video models, FreeInit significantly improves generation quality, marking a key advancement in overcoming noise initialization challenges in diffusion-based video generation.
FreeInit is a method addressing the initialization gap in video diffusion models by iteratively refining initial noise without additional training. Applied to publicly available text-to-video models, AnimateDiff, ModelScope, and VideoCrafter, FreeInit significantly enhances inference quality. The study also explores the impact of frequency filters, including Gaussian Low Pass Filter and Butterworth Low Pass Filter, on the balance between temporal consistency and visual quality in generated videos. Evaluation metrics include frame-wise similarity and the DINO metric, utilizing ViT-S16 DINO to assess temporal consistency and visual quality.
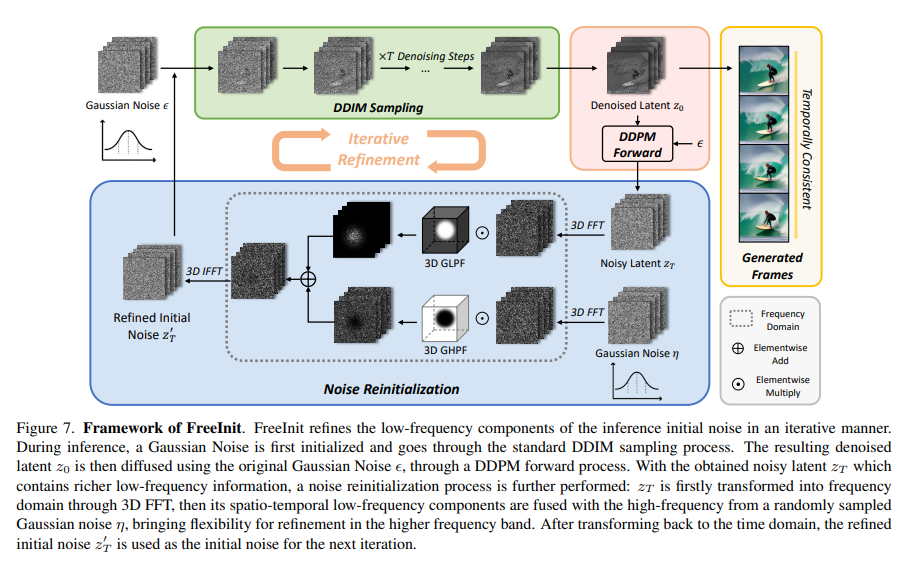
FreeInit markedly enhances temporal consistency in diffusion model-generated videos without extra training. It seamlessly integrates into various video diffusion models at inference, iteratively refining initial noise to bridge the training-inference gap. Evaluation of text-to-video models like AnimateDiff, ModelScope, and VideoCrafter reveals a substantial improvement in temporal consistency, ranging from 2.92 to 8.62. Quantitative assessments on UCF-101 and MSR-VTT datasets demonstrate FreeInit’s superiority, as indicated by performance metrics like DINO score, surpassing models without noise reinitialization or using different frequency filters.

To conclude, the complete study can be summarized in the following points:
- The research addresses a gap between training and inference in video diffusion models, which can affect inference quality.
- The researchers have proposed FreeInit, a concise and training-free sampling strategy.
- FreeInit enhances temporal consistency when applied to three text-to-video models, resulting in improved video generation without additional training.
- The study also explores frequency filters such as GLPF and Butterworth, further improving video generation.
- The results show that FreeInit offers a practical solution to enhance inference quality in video diffusion models.
- FreeInit is easy to implement and requires no extra training or learnable parameters.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
[ad_2]
Source link