[ad_1]

Image by Editor
Data science is a field that has grown tremendously in the last hundred years because of advancements made in the field of computer science. With computer and cloud storage costs getting cheaper, we are now able to store copious amounts of data at a very low cost compared to a few years ago. With the increase in computational power, we can run machine learning algorithms on large sets of data and churn it to produce insights. With advancements in networking, we can generate and transmit data over the internet at lightning speed. As a result of all of this, we live in an era with abundant data being generated every second. We have data in the form of email, financial transactions, social media content, web pages on the internet, customer data for businesses, medical records of patients, fitness data from smartwatches, video content on Youtube, telemetry from smart-devices and the list goes on. This abundance of data both in structured and unstructured format has made us land in a field called Data Mining.
Data Mining is the process of discovering patterns, anomalies, and correlations from large data sets to predict an outcome. While data mining techniques could be applied to any form of data, one such branch of Data Mining is Text Mining which refers to finding meaningful information from unstructured textual data. In this paper, I will focus on a common task in Text Mining to find Document Similarity.
Document Similarity helps in efficient information retrieval. Applications of document similarity include – detecting plagiarism, answering web search queries effectively, clustering research papers by topic, finding similar news articles, clustering similar questions in a Q&A site such as Quora, StackOverflow, Reddit, and grouping product on Amazon based on the description, etc. Document similarity is also used by companies like DropBox and Google Drive to avoid storing duplicate copies of the same document thereby saving processing time and storage cost.
There are several steps to computing document similarity. The first step is to represent the document in a vector format. We can then use pairwise similarity functions on these vectors. A similarity function is a function that computes the degree of similarity between a pair of vectors. There are several pairwise similarity functions such as – Euclidean Distance, Cosine Similarity, Jaccard Similarity, Pearson’s correlation, Spearman’s correlation, Kendall’s Tau, and so on [2]. A pairwise similarity function can be applied to two documents, two search queries, or between a document and a search query. While pairwise similarity functions suit well for comparing a smaller number of documents, there are other more advanced techniques such as Doc2Vec, BERT that are based on deep learning techniques and are used by search engines like Google for efficient information retrieval based on the search query. In this paper, I will focus on Jaccard Similarity, Euclidean Distance, Cosine Similarity, Cosine Similarity with TF-IDF, Doc2Vec, and BERT.
Pre-Processing
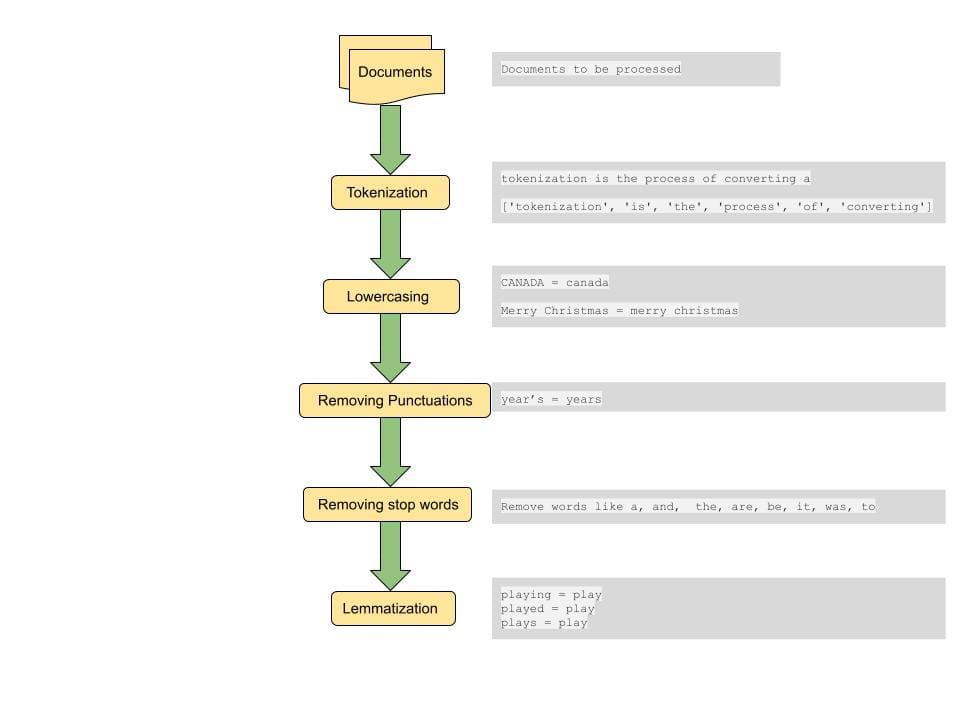
A common step to computing distance between documents or similarities between documents is to do some pre-processing on the document. The pre-processing step includes converting all text to lowercase, tokenizing the text, removing stop words, removing punctuations and lemmatizing words[4].
Tokenization: This step involves breaking down the sentences into smaller units for processing. A token is a smallest lexical atom that a sentence can be broken down into. A sentence can be broken down into tokens by using space as a delimiter. This is one way of tokenizing. For example, a sentence of the form “tokenization is a really cool step” is broken into tokens of the form [‘tokenization’, ‘is’, a, ‘really’, ‘cool’, ‘step’]. These tokens form the building blocks of Text Mining and are one of the first steps in modeling textual data..
Lowercasing: While preserving cases might be needed in some special cases, in most cases we want to treat words with different casing as one. This step is important in order to get consistent results from a large data set. For example if a user is searching for a word ‘india’, we want to retrieve relevant documents that contain words in different casing either as “India”, “INDIA” and “india” if they are relevant to the search query.
Removing Punctuations: Removing punctuation marks and whitespaces help focus the search on important words and tokens.
Removing stop words: Stop words are a set of words that are commonly used in the English language and removal of such words can help in retrieving documents that match more important words that convey the context of the query. This also helps in reducing the size of the feature vector thereby helping with processing time.
Lemmatization: Lemmatization helps in reducing sparsity by mapping words to their root word.For example ‘Plays’, ‘Played’ and ‘Playing’ are all mapped to play. By doing this we also reduce the size of the feature set and match all variations of a word across different documents to bring up the most relevant document.
This method is one of the easiest methods. It tokenizes the words and calculates the sum of the count of the shared terms to the sum of the total number of terms in both documents. If the two documents are similar the score is one, if the two documents are different the score is zero [3].
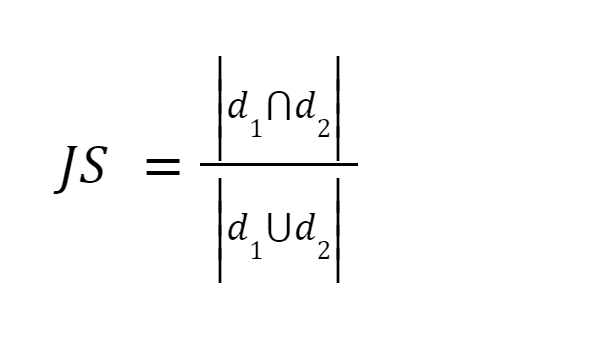
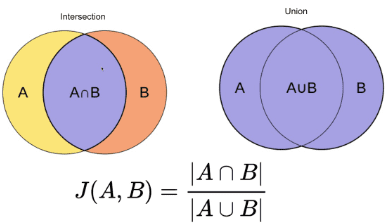
Image source: O’Reilly
Summary: This method has some drawbacks. As the size of the document increases, the number of common words will increase, even though the two documents are semantically different.
After pre-processing the document, we convert the document into a vector. The weight of the vector can either be the term frequency where we count the number of times the term appears in the document, or it can be the relative term frequency where we compute the ratio of the count of the term to the total number of terms in the document [3].
Let d1 and d2 be two documents represented as vectors of n terms (representing n dimensions); we can then compute the shortest distance between two documents using the pythagorean theorem to find a straight line between two vectors. The greater the distance, the lower the similarity;the lower the distance, the higher the similarity between two documents.
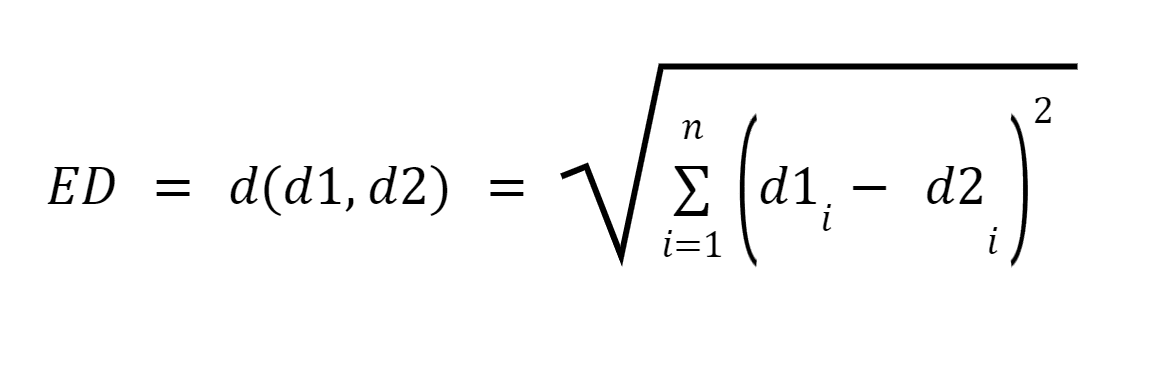
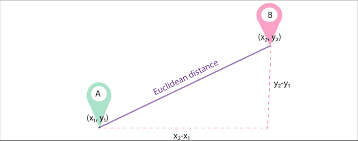
Image Source: Medium.com
Summary: Major drawback of this approach is that when the documents are differing in size, Euclidean Distance will give a lower score even though the two documents are similar in nature. Smaller documents will result in vectors with a smaller magnitude and larger documents will result in vectors with larger magnitude as the magnitude of the vector is directly proportional to the number of words in the document, thereby making the overall distance larger.
Cosine similarity measures the similarity between documents by measuring the cosine of the angle between the two vectors. Cosine similarity results can take value between 0 and 1. If the vectors point in the same direction, the similarity is 1, if the vectors point in opposite directions, the similarity is 0. [6].
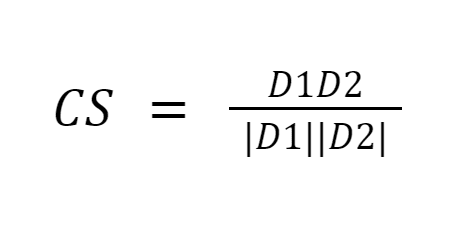
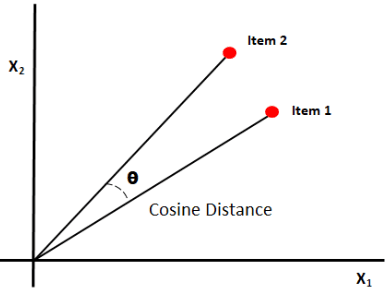
Image Source: Medium.com
Summary: The good thing about cosine similarity is that it computes the orientation between vectors and not the magnitude. Thus it will capture similarity between two documents that are similar despite being different in size.
The fundamental drawback of the above three approaches is that the measurement misses out on finding similar documents by semantics. Also, all of these techniques can only be done pairwise, thus requiring more comparisons .
This method of finding document similarity is used in default search implementations of ElasticSearch and it has been around since 1972 [4]. tf-idf stands for term frequency-inverse document frequency. We first compute the term frequency using this formula
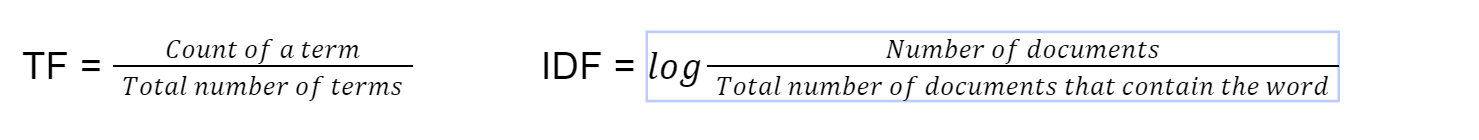
Finally we compute tf-idf by multiplying TF*IDF. We then use cosine similarity on the vector with tf-idf as the weight of the vector.
Summary: Multiplying the term frequency with the inverse document frequency helps offset some words which appear more frequently in general across documents and focus on words which are different between documents. This technique helps in finding documents that match a search query by focussing the search on important keywords.
Although using individual words (BOW – Bag of Words) from documents to convert to vectors might be easier to implement, it does not give any significance to the order of words in a sentence. Doc2Vec is built on top of Word2Vec. While Word2Vec represents the meaning of a word, Doc2Vec represents the meaning of a document or paragraph [5].
This method is used for converting a document into its vector representation while preserving the semantic meaning of the document. This approach converts variable-length texts such as sentences or paragraphs or documents to vectors [5]. The doc2vec mode is then trained. The training of the models is similar to training other machine learning models by picking training sets and test set documents and adjusting the tuning parameters to achieve better results.
Summary: Such a vectorised form of the document preserves the semantic meaning of the document as paragraphs with similar context or meaning will be closer together while converting to vector.
BERT is a transformer based machine learning model used in NLP tasks, developed by Google.
With the advent of BERT (Bidirectional Encoder Representations from Transformers), NLP models are trained with huge, unlabeled text corpora which looks at a text both from right to left and left to right. BERT uses a technique called “Attention” to improve results. Google’s search ranking improved by a huge margin after using BERT [4]. Some of the unique features of BERT include
- Pre-trained with Wikipedia articles from 104 languages.
- Looks at text both left to right and right to left
- Helps in understanding context
Summary: As a result, BERT can be fine-tuned for a lot of applications such as question-answering, sentence paraphrasing, Spam Classifier, Build language detector without substantial task-specific architecture modifications.
It was great to learn about how similarity functions are used in finding document similarity. Currently it is up to to the developer to pick a similarity function that best suits the scenario. For example tf-idf is currently the state of the art for matching documents while BERT is the state of the art for query searches. It would be great to build a tool that auto-detects which similarity function is best suited based on the scenario and thus pick a similarity function that is optimized for memory and processing time. This could greatly help in scenarios like auto-matching resumes to job descriptions, clustering documents by category, classifying patients to different categories based on patient medical records etc.
In this paper, I covered some notable algorithms to calculate document similarity. It is no way an exhaustive list. There are several other methods for finding document similarity and the decision to pick the right one depends on the particular scenario and use-case. Simple statistical methods like tf-idf, Jaccard, Euclidien, Cosine similarity are well suited for simpler use-cases. One can easily get setup with existing libraries available in Python, R and calculate the similarity score without requiring heavy machines or processing capabilities. More advanced algorithms like BERT depend on pre-training neural networks that can take hours but produce efficient results for analysis requiring understanding of the context of the document.
Reference
[1] Heidarian, A., & Dinneen, M. J. (2016). A Hybrid Geometric Approach for Measuring Similarity Level Among Documents and Document Clustering. 2016 IEEE Second International Conference on Big Data Computing Service and Applications (BigDataService), 1–5. https://doi.org/10.1109/bigdataservice.2016.14
[2] Kavitha Karun A, Philip, M., & Lubna, K. (2013). Comparative analysis of similarity measures in document clustering. 2013 International Conference on Green Computing, Communication and Conservation of Energy (ICGCE), 1–4. https://doi.org/10.1109/icgce.2013.6823554
[3] Lin, Y.-S., Jiang, J.-Y., & Lee, S.-J. (2014). A Similarity Measure for Text Classification and Clustering. IEEE Transactions on Knowledge and Data Engineering, 26(7), 1575–1590. https://doi.org/10.1109/tkde.2013.19
[4] Nishimura, M. (2020, September 9). The Best Document Similarity Algorithm in 2020: A Beginner’s Guide – Towards Data Science. Medium. https://towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
[5] Sharaki, O. (2020, July 10). Detecting Document Similarity With Doc2vec – Towards Data Science. Medium. https://towardsdatascience.com/detecting-document-similarity-with-doc2vec-f8289a9a7db7
[6] Lüthe, M. (2019, November 18). Calculate Similarity — the most relevant Metrics in a Nutshell – Towards Data Science. Medium. https://towardsdatascience.com/calculate-similarity-the-most-relevant-metrics-in-a-nutshell-9a43564f533e
[7] S. (2019, October 27). Similarity Measures — Scoring Textual Articles – Towards Data Science. Medium. https://towardsdatascience.com/similarity-measures-e3dbd4e58660
Poornima Muthukumar is a Senior Technical Product Manager at Microsoft with over 10 years of experience in developing and delivering innovative solutions for various domains such as cloud computing, artificial intelligence, distributed and big data systems. I have a Master’s Degree in Data Science from the University of Washington. I hold four Patents at Microsoft specializing in AI/ML and Big Data Systems and was the winner of the Global Hackathon in 2016 in the Artificial Intelligence Category. I was honored to be on the Grace Hopper Conference reviewing panel for the Software Engineering category this year 2023. It was a rewarding experience to read and evaluate the submissions from talented women in these fields and contribute to the advancement of women in technology, as well as to learn from their research and insights. I was also a committee member for the Microsoft Machine Learning AI and Data Science (MLADS) June 2023 conference. I am also an Ambassador at the Women in Data Science Worldwide Community and Women Who Code Data Science Community.
[ad_2]
Source link