[ad_1]
Diffusion models have become the prevailing approach for generating videos. Yet, their dependence on large-scale web data, which varies in quality, frequently leads to outcomes lacking visual appeal and not aligning well with the provided textual prompts. Despite advancements in recent times, there is still room for enhancing the visual quality of generated videos. One notable factor contributing to this challenge is the diverse quality of the extensive web data used in pre-training. This variability can result in models capable of producing content that lacks visual appeal, may be toxic, and does not align well with the provided prompts.
A team of researchers from Zhejiang University, Alibaba Group, Tsinghua University, Singapore University of Technology and Design, S-Lab, Nanyang Technological University, CAML Lab, and the University of Cambridge introduced InstructVideo to instruct text-to-video diffusion models with human feedback by reward fine-tuning. Comprehensive experiments, encompassing qualitative and quantitative assessments, confirm the practicality and effectiveness of incorporating image reward models in InstructVideo. This approach significantly improves the visual quality of generated videos without compromising the model’s ability to generalize.
Early efforts at video generation focused on GANs and VAEs, but generating videos from texts remained a challenge. Diffusion models have emerged as the de facto method for video generation, providing diversity and fidelity. VDM extended image diffusion models to video generation. Efforts were made to introduce spatiotemporal conditions for a more controllable generation. Understanding human preference in visual content generation is challenging, and some works use annotation and fine-tuning annotated data to model human preferences. Learning from human feedback in optical content generation is desirable, and previous works focused on reinforcement learning and agent alignment.
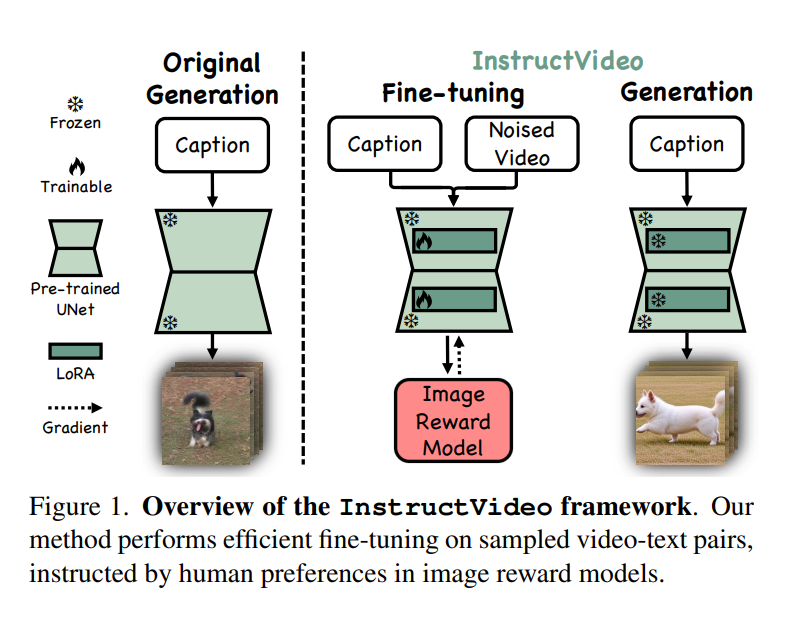
InstructVideo utilizes a reformulation of reward fine-tuning as editing, improving computational efficiency and efficacy. The method incorporates Segmental Video Reward (SegVR) and Temporally Attenuated Reward (TAR) to enable efficient reward fine-tuning using image reward models. SegVR provides reward signals based on segmental sparse sampling, while TAR mitigates temporal modeling degradation during fine-tuning. The optimization objective is rewritten to include the degree of the attenuating rate, with a default value of 1 for the coefficient. InstructVideo leverages the diffusion process to obtain the starting point for reward fine-tuning in video generation.

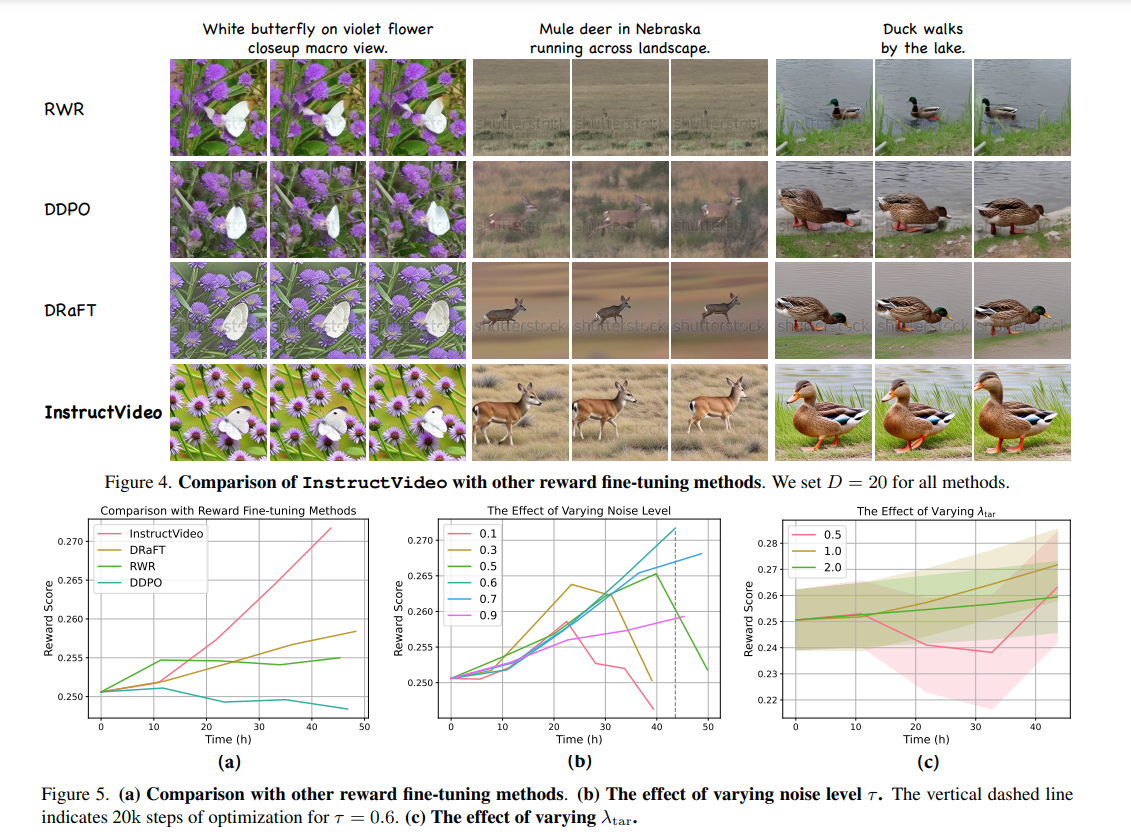
The research provides more visualization results to exemplify the conclusions drawn, showcasing how the generated videos evolve. The efficacy of InstructVideo is demonstrated through an ablation study on SegVR and TAR, showing that their removal leads to a noticeable reduction in temporal modeling capabilities. InstructVideo consistently outperforms other methods in terms of video quality, with improvements in video quality being more pronounced than improvements in video-text alignment.
In conclusion, the InstructVideo method significantly enhances the visual quality of generated videos without compromising generalization capabilities, as validated through extensive qualitative and quantitative experiments.InstructVideo outperforms other methods regarding video quality, with improvements in video quality being more pronounced than improvements in video-text alignment. Using image reward models, such as HPSv2, in InstructVideo proves practical and effective in enhancing the visual quality of generated videos. Incorporating SegVR and TAR in InstructVideo improves fine-tuning and mitigates temporal modeling degradation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
[ad_2]
Source link