[ad_1]

Image by Author
Before we get into the amazing things about Phi-2. If you haven’t already learnt about phi-1.5, I’d advise you to have a quick skim over what Microsoft had in the works a few months ago Effective Small Language Models: Microsoft’s 1.3 Billion Parameter phi-1.5.
Now you have the foundations, we can move on to learning more about Phi-2. Microsoft has been working hard to release a number of small language models (SLMs) called ‘Phi’. This series of models has been shown to achieve remarkable performance, just as it was a large language model.
Microsofts first model was Phi-1, the 1.3 billion parameter and then came Phi-1.5.
We’ve seen Phi-1, Phi-1.5, and now we have Phi-2.
Phi-2 has become bigger and better. Bigger and better. It is a 2.7 billion-parameter language model that has been shown to demonstrate outstanding reasoning and language understanding capabilities.
Amazing for a language model so small right?
Phi-2 has been shown to outperform models which are 25x larger. And that’s all thanks to model scaling and training data curation. Small, compact, and highly performant. Due to its size, Phi-2 is for researchers to explore interpretability, fine-tuning experiments and also delve into safety improvements. It is available on the Azure AI Studio model catalogue.
The Creation of Phi-2
Microsfts training data is a mixture of synthetic datasets which is used to teach the model common sense, such as general knowledge as well as science, theory of mind, and daily activities.
The training data was selected carefully to ensure that it was filtered with quality content that has educational value. That with the ability to scale has taken their 1.3 billion parameter model, Phi-1.5 to a 2.7 billion parameter Phi-2.
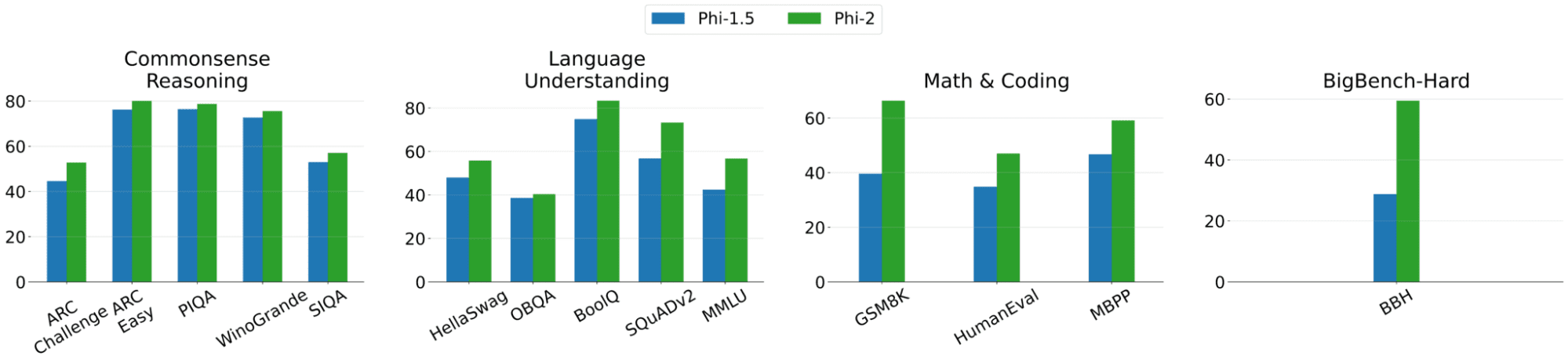
Image from Microsoft Phi-2
Microsoft put Phi-2 to the test, as they acknowledge the current challenges with model evaluation. Tests were done on use cases in which they compared it to Mistral and Llama-2. The results showed that Phi-2 outperformed Mistral-7B and the 70 billion Llama-2 model outperformed Phi-2 in some cases as shown below:
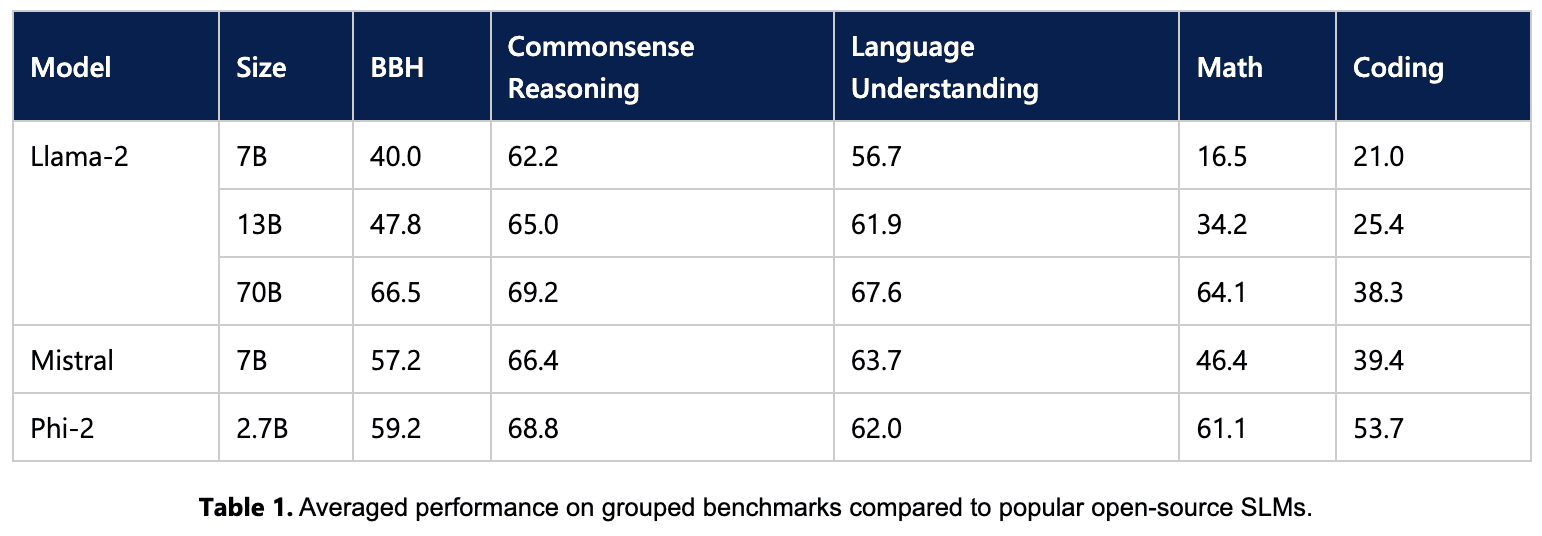
Image from Microsoft Phi-2
However, with that being said, Phi-2 still has its limitations. For example:
- Inaccuracy: the model has some limitations of producing incorrect code and facts, which users should take with a pinch of salt and treat these outputs as a starting point.
- Limited Code Knowledge: Phi-2 training data was based on Python along with using common packages, therefore the generation of other languages and scripts will need verification.
- Instructions: The model is yet to go through instruction fine-tuning, therefore it may struggle to really understand the instructions that the user provides.
There are also other limitations of Phi-2, such as language limitations, societal biases, toxicity, and verbosity.
With that being said, every new product or service has its limitations and Phi-2 has only been out for a week or so. Therefore, Microsoft will need phi-2 to get into the hands of the public to help them improve the service and overcome these current limitations.
Microsoft has ended the year with a small language model that could potentially grow to be the most talked about model of 2024. With this being said, to close the year – what should we expect from the language model world for the year 2024?
Nisha Arya is a Data Scientist and Freelance Technical Writer. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.
[ad_2]
Source link