[ad_1]
Task-agnostic model pre-training is now the norm in Natural Language Processing, driven by the recent revolution in large language models (LLMs) like ChatGPT. These models showcase proficiency in tackling intricate reasoning tasks, adhering to instructions, and serving as the backbone for widely used AI assistants. Their success is attributed to a consistent enhancement in performance with increased capacity or pre-training data. The remarkable scaling behavior of these models, especially when coupled with Transformer architectures, prompts an exploration beyond text. The inquiry revolves around whether applying an autoregressive objective to Vision Transformers (ViT) can achieve competitive performance and scalability similar to that of LLMs, marking an initial step towards generalizing findings beyond language modeling.
The application of autoregressive models spans diverse domains, focusing on language modeling and speech in existing literature. Investigations explore enhancing image autoregressive models through tailored architectures like convolution networks and transformers. Scaling with increased computing and data yields continuous improvements. The self-supervised pre-training methodologies encompass contrastive objectives and generative approaches such as autoencoders and GANs. The significance of scale in pre-training visual features is underscored, drawing comparisons to works like DINOv2 and revealing insights into the scaling law observed in language modeling.
The researchers from Apple present Autoregressive Image Models (AIM) as a large-scale pretraining approach for visual features. Building on prior work like iGPT, they leverage vision transformers, extensive web data collections, and recent advancements in LLM pre-training. AIM introduces two key modifications: adopting prefix attention for bidirectional self-attention and employing a heavily parameterized token-level prediction head inspired by contrastive learning. These adjustments enhance feature quality without substantial training overhead, aligning AIM’s methodology with recent LLM training approaches devoid of stability-inducing techniques used in supervised or self-supervised methods.

AIM adopts the Vision Transformer architecture, prioritizing width expansion for model capacity scaling. AIM employs causal masks for self-attention layers during pre-training, introducing a prefix attention mechanism for downstream tasks. The architecture incorporates Multilayer Perceptron (MLP) prediction heads, avoiding stability-inducing mechanisms. Sinusoidal positional embeddings are added, and AIM utilizes bfloat16 precision with the AdamW optimizer. Downstream adaptation involves fixed model weights and attention pooling for global descriptors, enhancing performance with minimal additional parameters.
AIM is compared with state-of-the-art methods across 15 diverse benchmarks. AIM outperforms generative counterparts, such as BEiT and MAE-H, and surpasses MAE-2B pre-trained on IG-3B, a private dataset. AIM demonstrates competitive performance with joint embedding methods like DINO, iBOT, and DINOv2, achieving high accuracy using simpler pre-training without relying on extensive tricks. The researchers have reported the IN-1k top-1 accuracy for features extracted from the last layer compared to the layer with the highest performance.
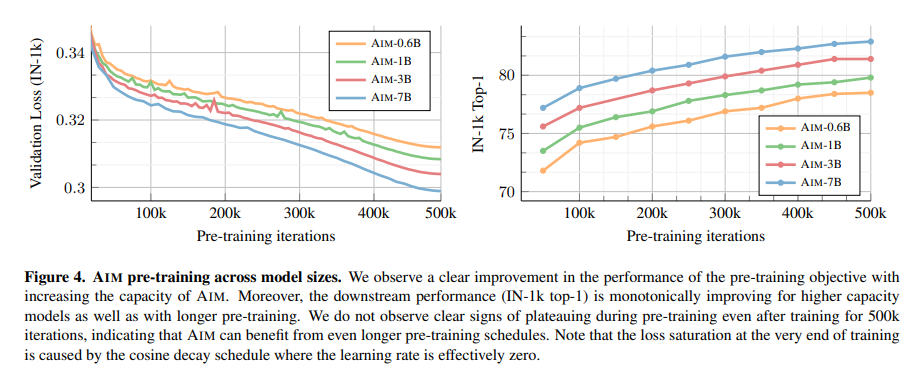
In conclusion, The researchers have introduced a simple and scalable unsupervised pre-training method, AIM, employing a generative autoregressive objective. AIM demonstrates effortless scaling to 7 billion parameters without complex stability-inducing techniques. Its strong correlation between pre-training and downstream performance, coupled with impressive results across 15 benchmarks, outperforming prior state-of-the-art methods, underscores its efficacy. There is potential for further improvements with larger models and longer training schedules, positioning AIM as a foundation for future research in scalable vision models leveraging uncurated datasets without bias.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
[ad_2]
Source link