[ad_1]
In today’s ever-expanding digital landscape, a vast amount of data is available at our fingertips. And this data continues to grow at a rapid pace. As of 2023, there were over 50 billion web pages online. The information on these websites must be scraped and extracted for many different business purposes, ranging from aiding small research projects to training LLMs that power AI models. Some of the largest businesses today started up through web scraping, and it continues to be key for them to stay competitive and ahead of the curve.
In this blog, we will discuss what web scraping is, how it works, which tools to use for web scraping, and how to pick the best web scraping tool for your business.
What is web scraping?
Web scraping is the process of extracting data from websites and storing it in a form useful for your business. Data extracted from websites is usually unstructured and needs to be converted into a structured form to be used for running analysis, research, or even training AI models.
If you have ever copied and pasted data from any website into an Excel spreadsheet or a Word document, essentially, it is web scraping at a very small scale. The copy-paste method is useful when web scraping needs to be done for personal projects or one-time use cases. However, when businesses need to scrape data from websites, they usually need to scrape from multiple websites, pages and also needs to be done repeatedly. Doing this manually would be extremely time-consuming and error-prone. Hence, organizations turn to web scraping tools that automatically extract data from websites based on business requirements. These tools can also transform data to make it useable, since most extracted data is unstructured, and upload it to the required destination.
Scrape data from Websites with Nanonets™ Website Scraping Tool for free.
How do web scrapers work?
A web scraper is a software that helps in extracting data from a website automatically. Web scrapers can extract all the data present on a website or only scrape data that is specified by the user. While the process of scraping may differ based on the web scraping tool being used, all web scrapers follow these basic rules:
- Once the target URL is specified and input into the web scraper, the scraper will make an HTTP request to the server.
- In response, the scraper will receive the HTML code of the target website. Advanced web scrapers can also receive CSS and Javascript elements.
- Extract relevant data from the HTML code. More advanced web scraping tools can also parse data from websites, i.e., only extract the required data and not all the information present.
- Save the extracted data in the target location. This could be an Excel spreadsheet, Word document, or even a database.
The web scraping process
The web scraping process follows a set of common principles across all tools and use cases. These principles stay the same for this entire web scraping process –
- Identify target URLs: Users need to manually select the URLs of websites that they want to extract data from and keep them ready to input into the web scraping tool.
- Scrape data from the websites: Once you input the website URL into the web scraping tool, the web scraper will retrieve and extract all the data on the website.
- Parse the extracted data: The data scraped from websites is usually unstructured and needs to be parsed to make it useful for analysis. This can be done manually or can be automated with the help of advanced web scraping tools.
- Upload/Save the final structured data: Once the data is parsed and structured into usable form, it can be saved to the desired location. This data can be uploaded into databases or saved as XLSX, CSV, TXT, or any other required format.
Looking to scrape data from websites? Try Nanonets™ Website Scraping Tool for free and quickly scrape data from any website.
Is web scraping legal?
While web scraping itself isn’t illegal, especially for publicly available data on a website, it’s important to tread carefully to avoid legal and ethical issues.
The key is respecting the website’s rules. Their terms of service (TOS) and robots.txt file might restrict scraping altogether or outline acceptable practices, like how often you can request data to avoid overwhelming their servers. Additionally, certain types of data are off-limits, such as copyrighted content or personal information without someone’s consent. Data scraping regulations like GDPR (Europe) and CCPA (California) add another layer of complexity.
Finally, web scraping for malicious purposes like stealing login credentials or disrupting a website is a clear no-go. By following these guidelines, you can ensure your web scraping activities are both legal and ethical.
How to scrape data from a website?
There are many ways to scrape data from websites. This blog will cover 5 ways in which data can be scraped from websites –
- Manually scrape data from a website
- Browser extensions for web scraping
- Automated no-code web scraping tools
- Web scraping with Python
- Using Microsoft Excel/Word to scrape data from websites
#1. Manually scrape data from a website
This is the most commonly used method to scrape data from a website. While this method is the simplest, it is also the most time-consuming and error-prone. The scraped data is often unstructured and difficult to process.
This method is best for a one-time use case. However, it is not feasible when web scraping is to be done for multiple websites or at regular intervals.
#2. Browser extensions for web scraping
Most browsers have many web scrapers available for free as browser extensions. These web scraping extensions can be added to the browser from its store and, while navigating a website, can help scrape data from it at a click.
While convenient, these browser extensions are not very accurate. The extracted data my be inconsistant. These tools can also not be automated and have the manual element of having to navigate to each page that needs to be extracted making them time consuming.
#3. Automated no-code web scraping tools
If you want to scrap data from a website to Excel automatically and instantly, try a no-code tool like Nanonets website scraper. This free web scraping tool can instantly scrape website data and convert it into an Excel format. Nanonets can also automate web scraping processes to remove any manual effort.
Here are three steps to scrape website data to Excel automatically using Nanonets:
Step 1: Head to Nanonets’ website scraping tool and insert your URL.
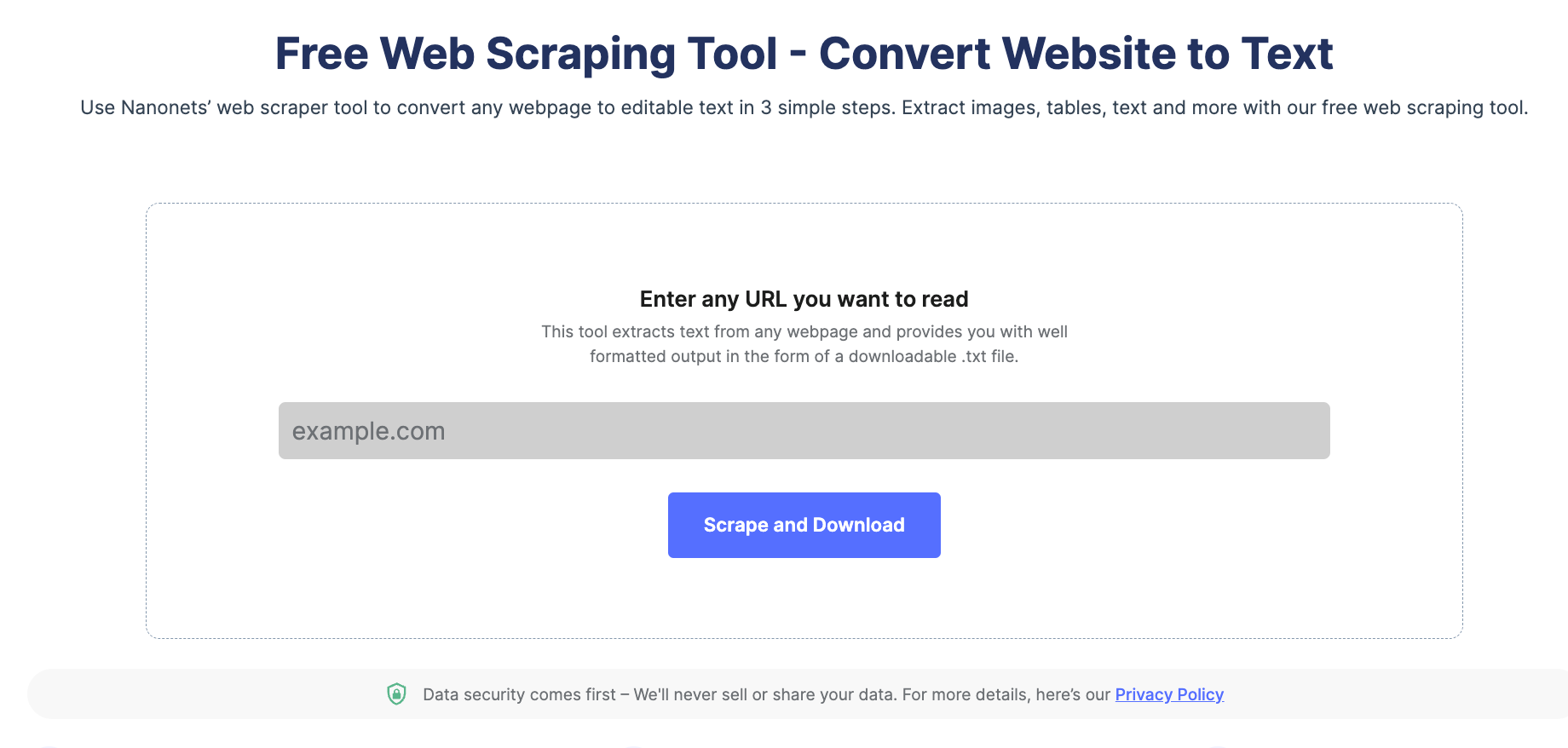
Step 2: Click on ‘Scrape and Download’.
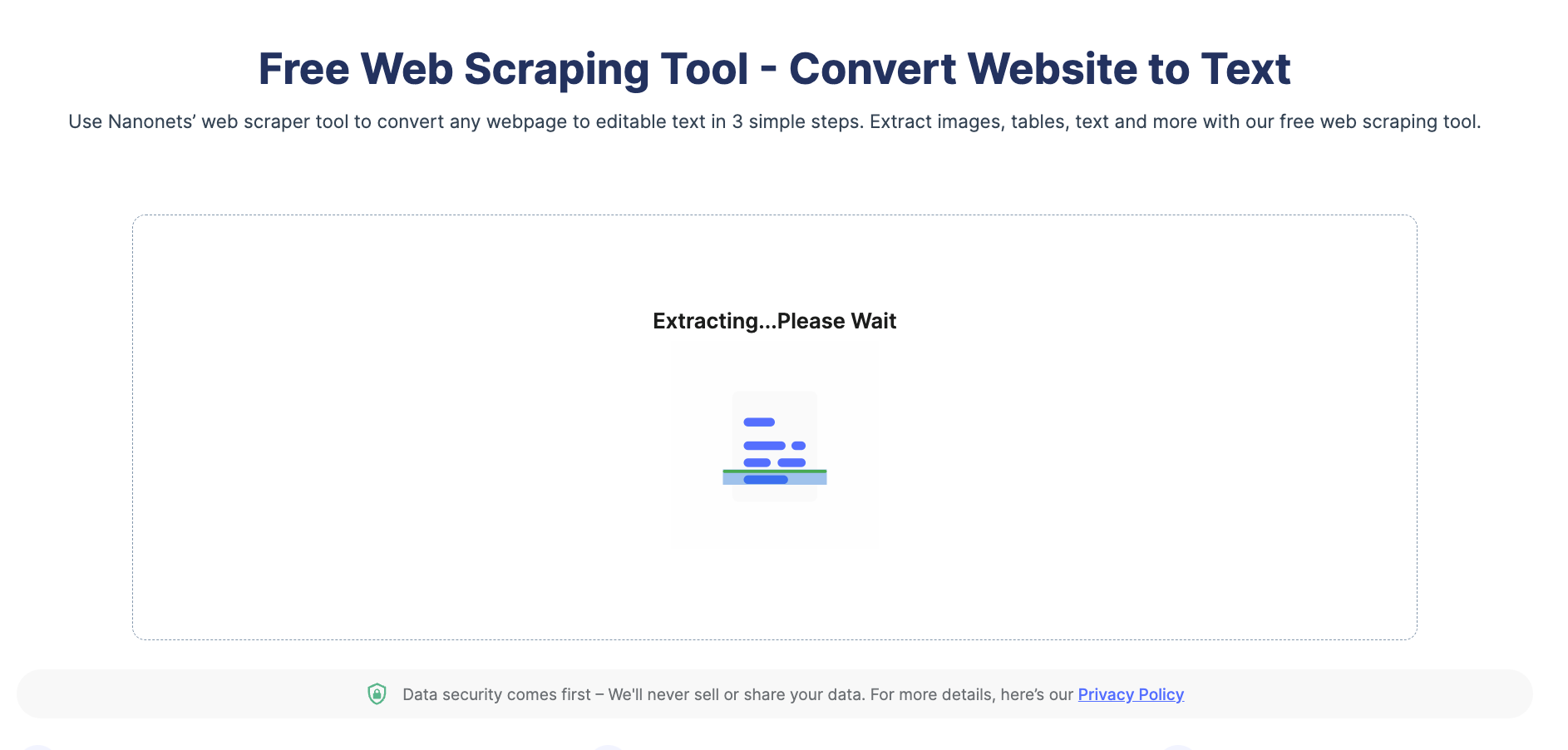
Step 3: Once done, the tool downloads the output file with the scraped website data automatically.
Scrape data from Websites with Nanonets™ Website Scraping Tool for free.
#4. Web scraping with Python
Web scraping with Python is popular owing to the abundance of third-party libraries that can scrape complex HTML structures, parse text, and interact with HTML form. Some popular Python web scraping libraries are listed below –
- Urllib3 is a powerful HTTP client library for Python. This makes it easy to perform HTTP requests programmatically. It handles HTTP headers, retries, redirects, and other low-level details, making it an excellent library for web scraping.
- BeautifulSoup allows you to parse HTML and XML documents. Using API, you can easily navigate through the HTML document tree and extract tags, meta titles, attributes, text, and other content. BeautifulSoup is also known for its robust error handling.
- MechanicalSoup automates the interaction between a web browser and a website efficiently. It provides a high-level API for web scraping that simulates human behavior. With MechanicalSoup, you can interact with HTML forms, click buttons, and interact with elements like a real user.
- Requests is a simple yet powerful Python library for making HTTP requests. It is designed to be easy to use and intuitive, with a clean and consistent API. With Requests, you can easily send GET and POST requests, and handle cookies, authentication, and other HTTP features. It is also widely used in web scraping due to its simplicity and ease of use.
- Selenium allows you to automate web browsers such as Chrome, Firefox, and Safari and simulate human interaction with websites. You can click buttons, fill out forms, scroll pages, and perform other actions. It is also used for testing web applications and automating repetitive tasks.
Pandas allow storing and manipulating data in various formats, including CSV, Excel, JSON, and SQL databases. Using Pandas, you can easily clean, transform, and analyze data extracted from websites.
#5. Using Microsoft Excel to scrape data from websites
You can scrape data from websites directly into Microsoft Excel in multiple ways. You can use Excel VBA or Excel Power Queries to import data from websites in an Excel spreadsheet. These tools are very powerful for extracting tabular data. However, when the data is slightly more unstructured, the extracted data may be imperfect or even incorrect.
Common use cases of web scraping
Web scraping has a multitude of uses across all industries. Some common use cases are listed below –
- Competitor research – Businesses scrape competitor websites to compare product offerings and monitor prices.
- Lead generation – Generating high-quality leads is extremely important to growing a business. Scraping websites is a good way to gather potential lead contact information – such as email addresses and phone numbers.
- Search Engine Optimization – Scraping webpages to monitor keyword rankings and analyze competitors’ SEO strategies.
- Sentiment analysis – Most online businesses scrape review sites and social media platforms to understand what customers are talking about and how they feel about their products and services.
- Legal and compliance. Companies scrape websites to ensure their content is not being used without permission or to monitor for counterfeit products.
- Real estate markets – Monitoring property listings and prices is crucial for real estate businesses to stay competitive.
- Integrations – Most applications use data that needs to be extracted from a website. Developers scrape websites to integrate this data into such applications, for example, scraping website data to train LLM models for AI development.
Which web scraping tool should you select? It depends on the kind of data that needs to be extracted and your use case for web scraping. We will recommend our top picks for choosing the best tool for your requirements.
Best online no-code web scraping tool: Nanonets
Best web scraping tools for one-time use: Nanonets web scarper chrome extension
Best web scraping tool for business: Nanonets
Best web scraping tool through API: BeautifulSoup Python Library
Eliminate bottlenecks caused by manually scraping data from websites. Find out how Nanonets can help you scrape data from websites automatically.
[ad_2]
Source link