[ad_1]
Multimodal Large Language Models (MLLMs) represent an advanced field in artificial intelligence where models integrate visual and textual information to understand and generate responses. These models have evolved from large language models (LLMs) that excelled in text comprehension and generation to now also processing and understanding visual data, enhancing their overall capabilities significantly.
The main problem addressed in this research is the need for more utilization of visual information in current MLLMs. Despite advancements in language processing, the visual component often needs to be expanded to high-level features extracted by a frozen visual encoder. This study seeks to explore how leveraging more detailed visual features can improve the performance of MLLMs, addressing the gap in fully utilizing visual signals for better multimodal understanding.
Current research includes various frameworks and models for MLLMs, such as CLIP, SigLIP, and Q-former, which connect visual and language models using pre-trained visual encoders and linear projections. Approaches like LLaVA and Mini-Gemini utilize high-resolution visual representations and instruction tuning to enhance performance. Methods such as Sparse Token Integration and Dense Channel Integration efficiently leverage multi-layer visual features to improve the robustness and scalability of MLLMs across diverse datasets and architectures.
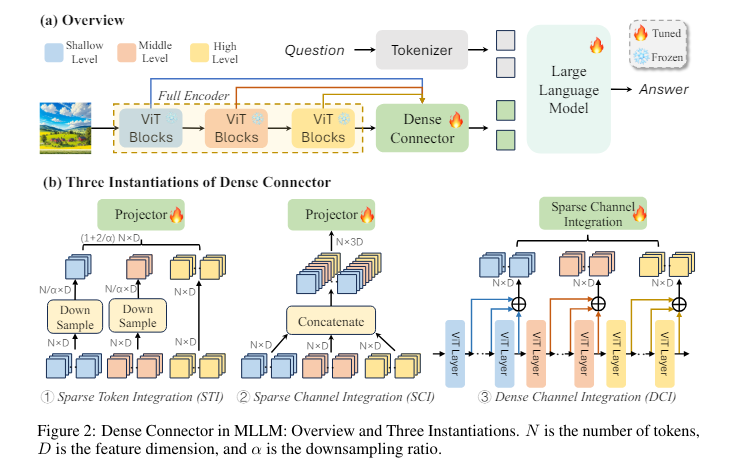
Researchers from Tsinghua University, Baidu Inc., The University of Sydney, Amazon Web Services, and The Chinese University of Hong Kong have introduced the Dense Connector, a vision-language connector that enhances MLLMs by leveraging multi-layer visual features. This approach involves minimal additional computational overhead and can be integrated seamlessly with existing MLLMs. This innovative connector addresses the limitations of current MLLMs by providing a more comprehensive integration of visual data into the language model.
The Dense Connector uses a plug-and-play mechanism that incorporates visual features from various layers of the frozen visual encoder, enhancing the input to the LLM. It offers three instantiations: Sparse Token Integration (STI), Sparse Channel Integration (SCI), and Dense Channel Integration (DCI). Each method utilizes visual tokens effectively to improve the robustness of visual embeddings fed into the LLM. STI increases the number of visual tokens by aggregating them from different layers and mapping them into the text space. SCI concatenates visual tokens from other layers in the feature dimension, reducing feature dimensionality while maintaining the number of tokens. DCI incorporates features from all layers, combining adjacent layers to avoid redundancy and high dimensionality.
The Dense Connector demonstrated remarkable zero-shot capabilities in video understanding and achieved state-of-the-art performance across 19 image and video benchmarks. It was tested with various vision encoders, image resolutions, and LLM sizes, ranging from 2.7 billion to 70 billion parameters, validating its versatility and scalability. Experimental results highlighted the Dense Connector’s ability to enhance visual representations in MLLMs with minimal computational cost. The model achieved significant improvements across various datasets, with pronounced enhancements of 2.9% on MMBench and 1.7% on GQA. The research team also conducted extensive empirical studies demonstrating its compatibility with different visual encoders, such as CLIP-ViT-L and SigLIP-ViT-SO, and varying training dataset scales.
Furthermore, the Dense Connector outperformed existing methods by leveraging high-resolution representations and integrating them using the DCI method. This approach yielded substantial performance gains across multiple benchmarks, including MathVista, MMBench, and MM-Vet, with improvements of 1.1%, 1.4%, and 1.4%, respectively. By applying the Dense Connector to high-resolution methods like Mini-Gemini, the researchers showcased its plug-and-play capability, significantly enhancing detail expression in MLLMs.

In conclusion, this research introduces the Dense Connector, a novel method that enhances MLLMs by effectively utilizing multi-layer visual features. This approach overcomes limitations in current MLLMs, where visual information is often restricted to high-level features. The Dense Connector offers several instantiations, each integrating visual data from different layers of the visual encoder. This improves the quality of visual information fed into the LLM without significant computational cost. Experiments demonstrate that the Dense Connector significantly improves MLLM performance on various image and video benchmarks, highlighting its potential to advance multimodal understanding in AI.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
[ad_2]
Source link