[ad_1]
Recent advancements in video generation have been driven by large models trained on extensive datasets, employing techniques like adding layers to existing models and joint training. Some approaches use multi-stage processes, combining base models with frame interpolation and super-resolution. Video Super-Resolution (VSR) enhances low-resolution videos, with newer techniques using varied degradation models to better mimic real-world data. Space-Time Video Super-Resolution (STVSR) aims to improve both clarity and frame rate, though many methods still struggle with realistic texture details. These developments are pushing the boundaries of video quality enhancement and generation capabilities.
Recent advancements in video technology include VEnhancer, a new tool that improves low-quality videos by enhancing details and motion. It uses a specialized space-time video model to address common issues like blurriness and flickering. VEnhancer’s trained model has demonstrated superior performance compared to other methods, contributing to a popular video generation tool’s top benchmark results. This innovation, along with other developments in Video Super-Resolution and Space-Time Video Super-Resolution, is significantly advancing the field of video quality enhancement and generation.
Researchers from The Chinese University of Hong Kong, Shanghai AI Laboratory, and S-Lab, Nanyang Technological University have identified key challenges in video enhancement and generation. Recent advancements in this field have been driven by improvements in text-to-image models and large text-video datasets, enabling video creation from textual descriptions. While cascaded pipelines combining various super-resolution models are common, they face issues such as redundancy and poor flexibility. Existing diffusion-based models struggle with generalization and adaptability to different video scenarios. These limitations underscore the need for an integrated solution like VEnhancer to effectively enhance video quality across multiple dimensions simultaneously, addressing both spatial and temporal aspects in a unified approach.
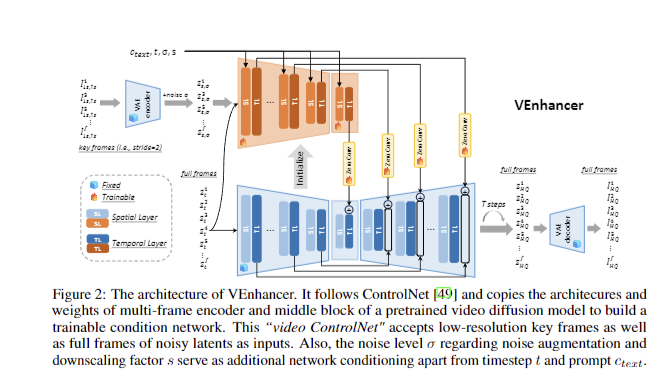
Researchers collected approximately 350,000 high-quality video clips from the Internet for training, processed at 720 × 1280 resolution and 24 FPS. They assembled the AIGC2023 test dataset, featuring diverse generated videos from state-of-the-art text-to-video methods. The evaluation employed non-reference IQA and VQA metrics (MUSIQ, DOVER) and the VBench benchmark. Training utilised a batch size of 256, AdamW optimizer, 10^-5 learning rate, and 10% text prompt dropout over four days on 16 NVIDIA A100 GPUs. Inference involved 50 DDIM sampling steps with classifier-free guidance. Space-time data augmentation and a trainable video ControlNet were implemented to enhance model robustness and performance across various input conditions.

VEnhancer successfully integrated spatial super-resolution, temporal super-resolution, and video refinement into a unified framework, leveraging a pretrained video diffusion model and a trainable video ControlNet. Extensive experiments demonstrated its superior performance over state-of-the-art video and space-time super-resolution methods, significantly enhancing AI-generated videos. VEnhancer elevated VideoCrafter-2 to the top position in the VBench video generation benchmark. Evaluation using IQA and VQA metrics (MUSIQ, DOVER) confirmed its effectiveness. However, limitations were identified, including longer inference time compared to one-step methods and challenges in maintaining long-term consistency for videos exceeding 10 seconds. The model, trained on 350,000 high-quality video clips, showed robust performance on the diverse AIGC2023 test dataset, highlighting its potential for advancing video enhancement technology.

In conclusion, VEnhancer marks a significant advancement in video enhancement technology by introducing a unified generative space-time enhancement method. This novel approach effectively combines spatial and temporal super-resolution with video refinement, utilizing a pretrained video diffusion model and trainable video ControlNet. The framework demonstrates superior performance over existing state-of-the-art methods, notably elevating VideoCrafter-2 to the top position in the VBench video generation benchmark. While VEnhancer showcases impressive capabilities in improving AI-generated video quality, it also reveals areas for future improvement, such as optimizing inference times and enhancing long-term consistency for extended videos. These findings not only underscore VEnhancer’s current potential but also illuminate promising directions for future research in the rapidly evolving field of video generation and enhancement.
Check out the Paper, GitHub, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI

[ad_2]
Source link