[ad_1]
Large-scale pretraining followed by task-specific fine-tuning has revolutionized language modeling and is now transforming computer vision. Extensive datasets like LAION-5B and JFT-300M enable pre-training beyond traditional benchmarks, expanding visual learning capabilities. Notable models such as DINOv2, MAWS, and AIM have made significant strides in self-supervised feature generation and masked autoencoder scaling. However, existing methods often overlook human-centric approaches, focusing primarily on general image pretraining or zero-shot classification.
This paper introduces Sapiens, a collection of high-resolution vision transformer models pretrained on millions of human images. Unlike previous work, which has not scaled vision transformers to the same extent as large language models, Sapiens addresses this gap by leveraging the Humans-300M dataset. This diverse collection of 300 million human images allows for the study of pre-training data distribution’s impact on downstream human-specific tasks. By emphasizing human-centric pretraining, Sapiens aims to advance the field of computer vision in areas such as 3D human digitization, keypoint estimation, and body-part segmentation, which are crucial for real-world applications.
The paper introduces a novel approach to human-centric computer vision through Sapiens, a family of vision transformer models. This approach combines large-scale pretraining on human images with high-quality annotations, achieving robust generalization, broad applicability, and high fidelity in real-world scenarios. The methodology employs simple data curation and pretraining, yielding significant performance improvements. Sapiens supports high-fidelity inference at 1K resolution, achieving state-of-the-art results on various benchmarks. As a potential foundational model for downstream tasks, Sapiens demonstrates the effectiveness of domain-specific pretraining in computer vision, with future work potentially extending to 3D and multi-modal datasets.
The Sapiens models employ a multifaceted methodology focusing on large-scale pretraining, high-quality annotations, and architectural innovations. The approach utilizes a curated dataset for human-centric tasks, emphasizing precise annotations with 308 key points for pose estimation and 28 segmentation classes. The architectural design prioritizes width scaling over depth, enhancing performance without significant computational cost increases. The methodology incorporates layer-wise learning rate decay and weight decay optimization. It emphasizes generalization across varied environments and utilizes synthetic data for depth and normal estimation. This strategic combination creates robust models capable of performing diverse human-centric tasks effectively in real-world scenarios, addressing challenges in existing public benchmarks and enhancing model adaptability.

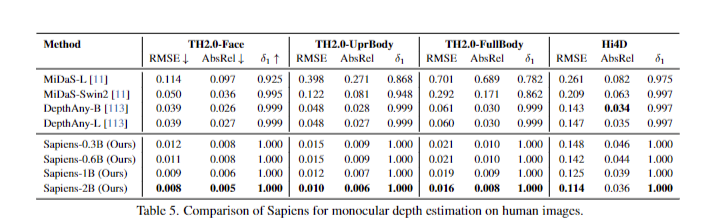
The Sapiens models underwent comprehensive evaluation across four primary tasks: pose estimation, part segmentation, depth estimation, and normal estimation. Pretraining with the Human 300M dataset led to superior performance across all metrics. Performance was quantified using mAP for pose estimation, mIoU for segmentation, RMSE for depth estimation, and mean angular error for normal estimation. Increasing pre-training dataset size consistently improved performance, demonstrating a correlation between data diversity and model generalization. The models exhibited robust generalization capabilities across various in-the-wild scenarios. Overall, Sapiens demonstrated strong performance in all evaluated tasks, with improvements linked to pretraining data quality and quantity. These results affirm the efficacy of the Sapiens methodology in creating precise and generalizable human vision models.
In conclusion, Sapiens represents a significant advancement in human-centric vision models, demonstrating strong generalization across various tasks. Its exceptional performance stems from large-scale pretraining on a curated dataset, high-resolution vision transformers, and high-quality annotations. Positioned as a foundational element for downstream tasks, Sapiens makes high-quality vision backbones more accessible. Future work may extend to 3D and multi-modal datasets. The research emphasizes that combining domain-specific large-scale pretraining with limited high-quality annotations leads to robust real-world generalization, reducing the need for extensive annotation sets. Sapiens thus emerges as a transformative model in human-centric vision, offering significant potential for future research and applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI
[ad_2]
Source link