[ad_1]

Image by Author | Canva
Language translation has become an essential tool in our increasingly globalized world. Whether you’re a developer, researcher, or traveler, you will always find the need to communicate with people from different cultures. Hence, the ability to translate text quickly and accurately can be very helpful for you. One powerful resource for achieving this is the MarianMT model, a part of the Hugging Face Transformers library.
In this guide, we will walk you through the process of using MarianMT to translate text between multiple languages, making it accessible even for those with minimal technical background.
What is MarianMT?
MarianMT is a machine translation framework based on the Transformer architecture, which is widely recognized for its effectiveness in natural language processing tasks. Developed using the Marian C++ library, the MarianMT models have a huge advantage of being fast. Hugging Face has incorporated MarianMT into their Transformers library, making it easier to access and use through Python.
Step-by-Step Guide to Use MarianMT
1. Installation
To begin, you need to install the necessary libraries. Ensure you have Python installed on your system, then run the following command to install the Hugging Face Transformers library:
You’ll also need the torch library for handling the model’s computations:
2. Choosing a Model
MarianMT models are pre-trained on various language pairs. The models follow a naming convention of Helsinki-NLP/opus-mt-{src}-{tgt} in hugging face, where {src} and {tgt} are the source and target language codes, respectively. For example, if you search Helsinki-NLP/opus-mt-en-fr in hugging face, the corresponding model would translate from English to French.
3. Loading the Model and Tokenizer
Let’s say you decide to translate English to a specific language, i.e., French. Then you would need to load the right model and its corresponding tokenizer. Here’s how you load the model and tokenizer:
from transformers import MarianMTModel, MarianTokenizer
# Specify the model name
model_name = "Helsinki-NLP/opus-mt-en-fr"
# Load the tokenizer and model
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
4. Translating Text
Now that you have your model and tokenizer ready, you can translate text in just 4 simple steps! Here’s a basic example.First of all, you would specify the source text in a variable that you want to translate.
# Define the source text
src_text = ["this is a sentence in English that we want to translate to French"]
Since transformers (or any machine learning model) does not understand text, we want to convert the source text into numeric form. For that, we would tokenize our text. For a thorough understanding of how to do tokenization, you can refer to my Tokenization article.
# Tokenize the source text
inputs = tokenizer(src_text, return_tensors="pt", padding=True)
Then we’ll pass the tokenized sentence to the model and it will output some numbers.
# Generate the translation
translated = model.generate(**inputs)
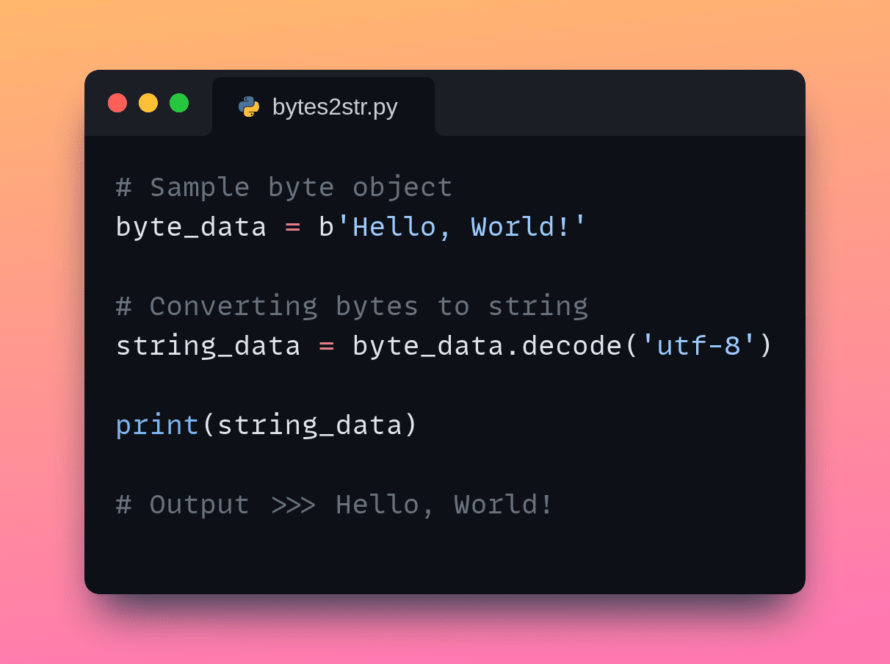
Notice that model outputs tokens, and not text directly. We would have to decode these tokens back to text so humans can understand the translated output of the model.
# Decode the translated text
tgt_text = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
print(tgt_text)
In the above code, the output will be the translated text in French:
c'est une phrase en anglais que nous voulons traduire en français
5. Translating to Multiple Languages
If you want to translate English text into multiple languages, you can use multilingual models. For example, the model Helsinki-NLP/opus-mt-en-ROMANCE can translate english to several Romance languages (French, Portuguese, Spanish, etc.). Specify the target language by prepending the source text with the target language code:
src_text = [
">>fr<< this is a sentence in English that we want to translate to French",
">>pt<< This should go to Portuguese",
">>es<< And this to Spanish",
]
# Specify the multilingual model
model_name = "Helsinki-NLP/opus-mt-en-ROMANCE"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
# Tokenize the source text
inputs = tokenizer(src_text, return_tensors="pt", padding=True)
# Generate the translations
translated = model.generate(**inputs)
# Decode the translated text
tgt_text = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
print(tgt_text)
Output would look like this:
["c'est une phrase en anglais que nous voulons traduire en français",
'Isto deve ir para o português.',
'Y esto al español']
With this setup, you can easily translate your English text into French, Portuguese, and Spanish. There are some groups of languages other than ROMANCE languages as well. Here is a list of them:
GROUP_MEMBERS = {
'ZH': ['cmn', 'cn', 'yue', 'ze_zh', 'zh_cn', 'zh_CN', 'zh_HK', 'zh_tw', 'zh_TW', 'zh_yue', 'zhs', 'zht', 'zh'],
'ROMANCE': ['fr', 'fr_BE', 'fr_CA', 'fr_FR', 'wa', 'frp', 'oc', 'ca', 'rm', 'lld', 'fur', 'lij', 'lmo', 'es', 'es_AR', 'es_CL', 'es_CO', 'es_CR', 'es_DO', 'es_EC', 'es_ES', 'es_GT', 'es_HN', 'es_MX', 'es_NI', 'es_PA', 'es_PE', 'es_PR', 'es_SV', 'es_UY', 'es_VE', 'pt', 'pt_br', 'pt_BR', 'pt_PT', 'gl', 'lad', 'an', 'mwl', 'it', 'it_IT', 'co', 'nap', 'scn', 'vec', 'sc', 'ro', 'la'],
'NORTH_EU': ['de', 'nl', 'fy', 'af', 'da', 'fo', 'is', 'no', 'nb', 'nn', 'sv'],
'SCANDINAVIA': ['da', 'fo', 'is', 'no', 'nb', 'nn', 'sv'],
'SAMI': ['se', 'sma', 'smj', 'smn', 'sms'],
'NORWAY': ['nb_NO', 'nb', 'nn_NO', 'nn', 'nog', 'no_nb', 'no'],
'CELTIC': ['ga', 'cy', 'br', 'gd', 'kw', 'gv']
}
Wrapping Up
Using MarianMT models with the Hugging Face Transformers library provides a powerful and flexible way to perform language translations. Whether you’re translating text for personal use, research, or integrating translation capabilities into your applications, MarianMT offers a reliable and easy-to-use solution. With the steps outlined in this guide, you can get started with translating languages efficiently and effectively.
Kanwal Mehreen Kanwal is a machine learning engineer and a technical writer with a profound passion for data science and the intersection of AI with medicine. She co-authored the ebook “Maximizing Productivity with ChatGPT”. As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She’s also recognized as a Teradata Diversity in Tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having founded FEMCodes to empower women in STEM fields.
[ad_2]
Source link