[ad_1]
The progress in neural rendering has brought significant breakthroughs in reconstructing scenes and generating new viewpoints. However, its effectiveness largely depends on the precise pre-computation of camera poses. To minimize this problem, many efforts have been made to train Neural Radiance Fields (NeRFs) without precomputed camera poses. However, the implicit representation of NeRFs makes it difficult to optimize the 3D structure and camera poses simultaneously.
Researchers from UC San Diego, NVIDIA, and UC Berkeley introduced COLMAP-Free 3D Gaussian Splatting (CF-3DGS), which enhances two key ingredients: the temporal continuity from video and the explicit point cloud representation. Instead of optimizing with all frames at once, CF-3DGS built the 3D Gaussians of the scene in a continuous form, “growing” one structure at a time as the camera moves. CF-3DGS extracts a local 3D Gaussian set for each frame and maintains a global 3D Gaussian set of the entire scene.

Different 3D scene representations have been employed to generate realistic images from viewpoints, including planes, meshes, point clouds, and multi-plane images.NeRFs (Neural Radiance Fields) have gained prominence in this field due to their exceptional capability of photorealistic rendering. The 3DGS (3D Gaussian Splatting) method enables real-time rendering of views using a pure explicit representation and a differential point-based splatting method.
CF-3DGS synthesis view without known camera parameters. It optimizes the 3D Gaussian Splatting (3DGS) and camera poses simultaneously. It uses a local 3DGS method to estimate relative camera pose from nearby frames and a global 3DGS process for the progressive expansion of 3D Gaussians from unobserved views.CF-3DGS utilizes explicit point clouds to represent scenes and leverages the capabilities of 3DGS and the continuity inherent in video streams. It sequentially processes input frames, progressively expanding the 3D Gaussians to reconstruct the scene. This approach achieves rapid training and inference speeds.
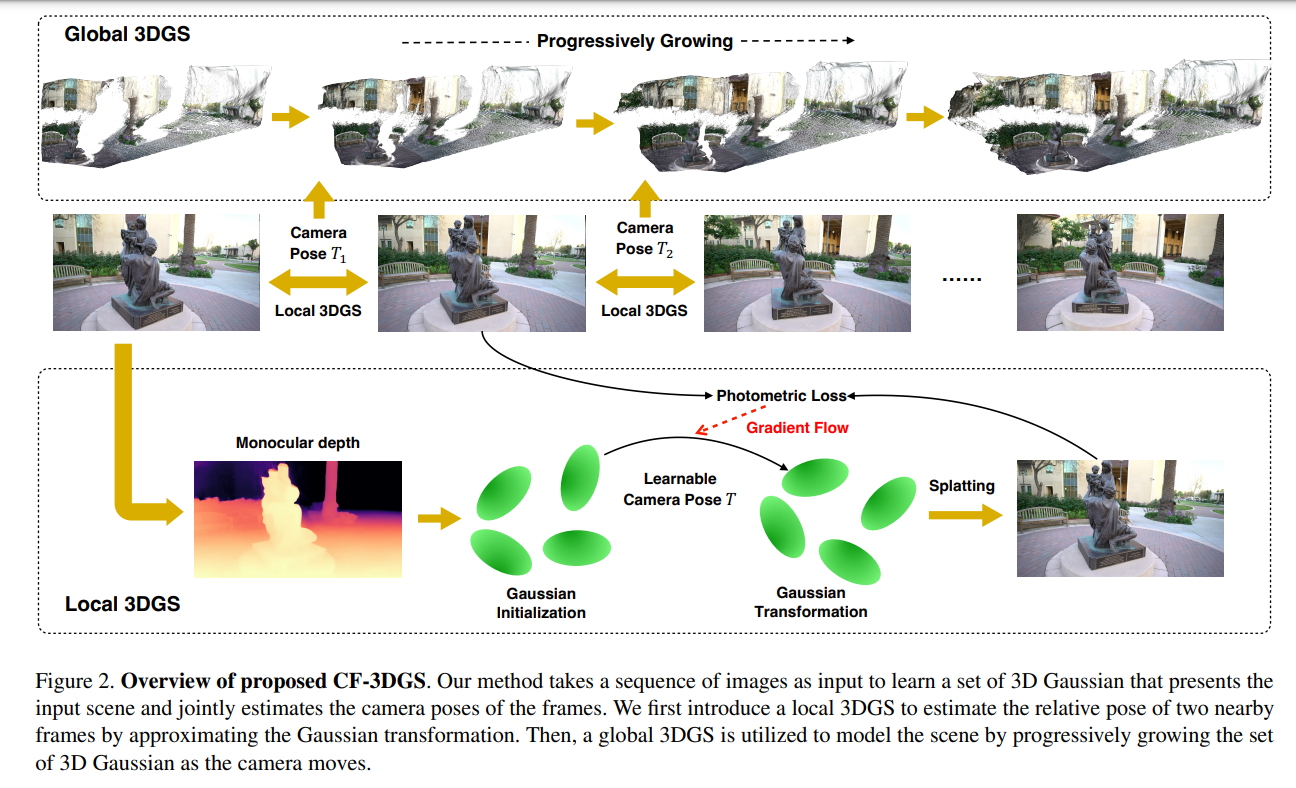
CF-3DGS method achieves more robustness in pose estimation and better quality in novel view synthesis than previous state-of-the-art methods. The method is validated on the CO3D videos, which present more complex and challenging camera movements, and it outperforms the Nope-NeRF method in terms of view synthesis quality. The approach consistently surpasses Nope-NeRFe across all metrics in camera pose estimation on the CO3D V2 dataset, demonstrating its robustness and accuracy in estimating camera poses, especially in scenarios with complex camera movements.
To conclude, CF-3DGS is a method that effectively and robustly synthesizes views using video’s temporal continuity and explicit point cloud representation without the need for Structure-from-Motion (SfM) preprocessing. It optimizes camera pose and 3DGS jointly, making it suitable primarily for video streams or ordered image collections. It also has the potential for future extensions to accommodate unordered image collections.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
[ad_2]
Source link