[ad_1]
The focus has shifted towards multimodal Large Language Models (MLLMs), particularly in enhancing their processing and integrating multi-sensory data in the evolution of AI. This advancement is crucial in mimicking human-like cognitive abilities for complex real-world interactions, especially when dealing with rich visual inputs.
A key challenge in the current MLLMs is their need for high-resolution and visually dense images. These models typically depend on pre-trained vision encoders, constrained by low-resolution training, leading to a significant loss of crucial visual details. This limitation hinders their ability to provide precise visual grounding, which is essential for complex task execution.
MLLMs have adopted two primary approaches earlier. Some connect a pre-trained language model with a vision encoder, projecting visual features into the language model’s input space. Others treat the language model as a tool, accessing various vision expert systems to perform vision-language tasks. However, both methods suffer from significant drawbacks, such as information loss and inaccuracy, mainly when dealing with detailed visual data.
Researchers from UC San Diego and New York University have developed SEAL (Show, sEArch, and telL), a framework that introduces an LLM-guided visual search mechanism into MLLMs. This approach substantially enhances MLLMs’ capabilities to identify and process necessary visual information. SEAL comprises a Visual Question Answering Language Model and a Visual Search Model. It leverages the extensive world knowledge embedded in language models to identify and locate specific visual elements within high-resolution images. Once these elements are found, they are incorporated into a Visual Working Memory. This integration allows for a more accurate and contextually informed response generation, overcoming the limitations faced by traditional MLLMs.
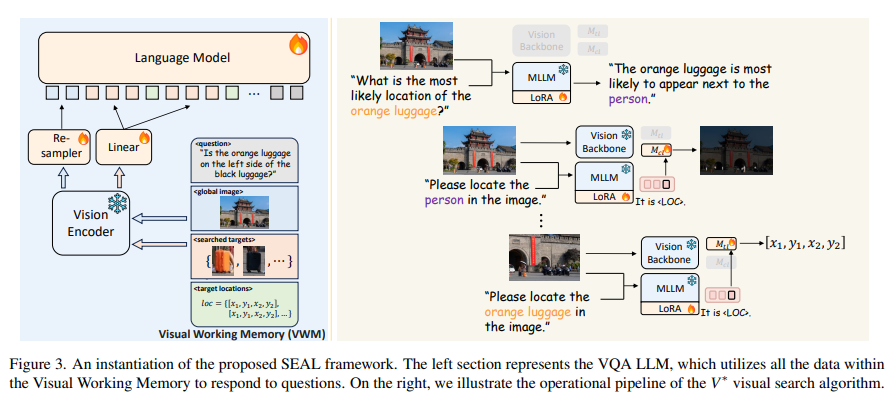
The efficacy of the SEAL framework, particularly its visual search algorithm, is evident in its performance. Compared to existing models, SEAL shows a marked improvement in detailed graphical analysis. It successfully addresses the shortcomings of current MLLMs by accurately grounding visual information in complex images. The visual search algorithm enhances the MLLMs’ ability to focus on critical visual details, a fundamental human cognition mechanism lacking in AI models. By incorporating these capabilities, SEAL sets a new standard in the field, demonstrating a significant leap forward in multimodal reasoning and processing.

In conclusion, introducing the SEAL framework and its visual search algorithm marks a significant milestone in MLLM development. Key takeaways from this research include:
- SEAL’s integration of an LLM-guided visual search mechanism fundamentally enhances MLLM’s processing of high-resolution images.
- The framework’s ability to actively search and process visual information leads to more accurate and contextually relevant responses.
- Despite its advancements, there remains room for further improvement in architectural design and application across different visual content types.
- Future developments might focus on extending SEAL’s application to document and diagram images, long-form videos, or open-world environments.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
[ad_2]
Source link