[ad_1]
Text-to-image generation is a unique field where language and visuals converge, creating an interesting intersection in the ever-changing world of AI. This technology converts textual descriptions into corresponding images, merging the complexities of understanding language with the creativity of visual representation. As the field matures, it encounters challenges, particularly in generating high-quality images efficiently from textual prompts. This efficiency is not just about speed but also about the computational resources required, impacting the practical application of such technology.
Traditionally, text-to-image generation has relied heavily on models like latent diffusion. These models operate by iteratively reducing noise from an image, simulating a reverse diffusion process. While they have successfully created detailed and accurate images, they come with a cost – computational intensity and a lack of interpretability. Researchers have been investigating other approaches that could balance efficiency and quality.
Meet aMUSEd: a breakthrough in this field developed by a Hugging Face and Stability AI collaborative team. This innovative model is a streamlined version of the MUSE framework, designed to be lightweight yet effective. What sets aMUSEd apart is its significantly reduced parameter count, which stands at just 10% of MUSE’s parameters. This reduction is a deliberate move to enhance image generation speed without compromising the output quality.
The core of aMUSEd’s methodology lies in its unique architectural choices. It integrates a CLIP-L/14 text encoder and employs a U-ViT backbone. The U-ViT backbone is crucial as it eliminates the need for a super-resolution model, a common requirement in many high-resolution image generation processes. By doing so, aMUSEd simplifies the model structure and reduces the computational load, making it a more accessible tool for various applications. The model is trained to generate images directly at resolutions of 256×256 and 512×512, showcasing its ability to produce detailed visuals without requiring extensive computational resources.
When it comes to performance, aMUSEd sets new standards in the field. Its inference speed outshines that of non-distilled diffusion models and is on par with some of the few-step distilled diffusion models. This speed is crucial for real-time applications and demonstrates the model’s practical viability. Moreover, aMUSEd excel in tasks like zero-shot in-painting and single-image style transfer, showcasing its versatility and adaptability. In tests, the model has shown particular prowess in generating less detailed images, such as landscapes, indicating its potential for applications in areas like virtual environment design and quick visual prototyping.
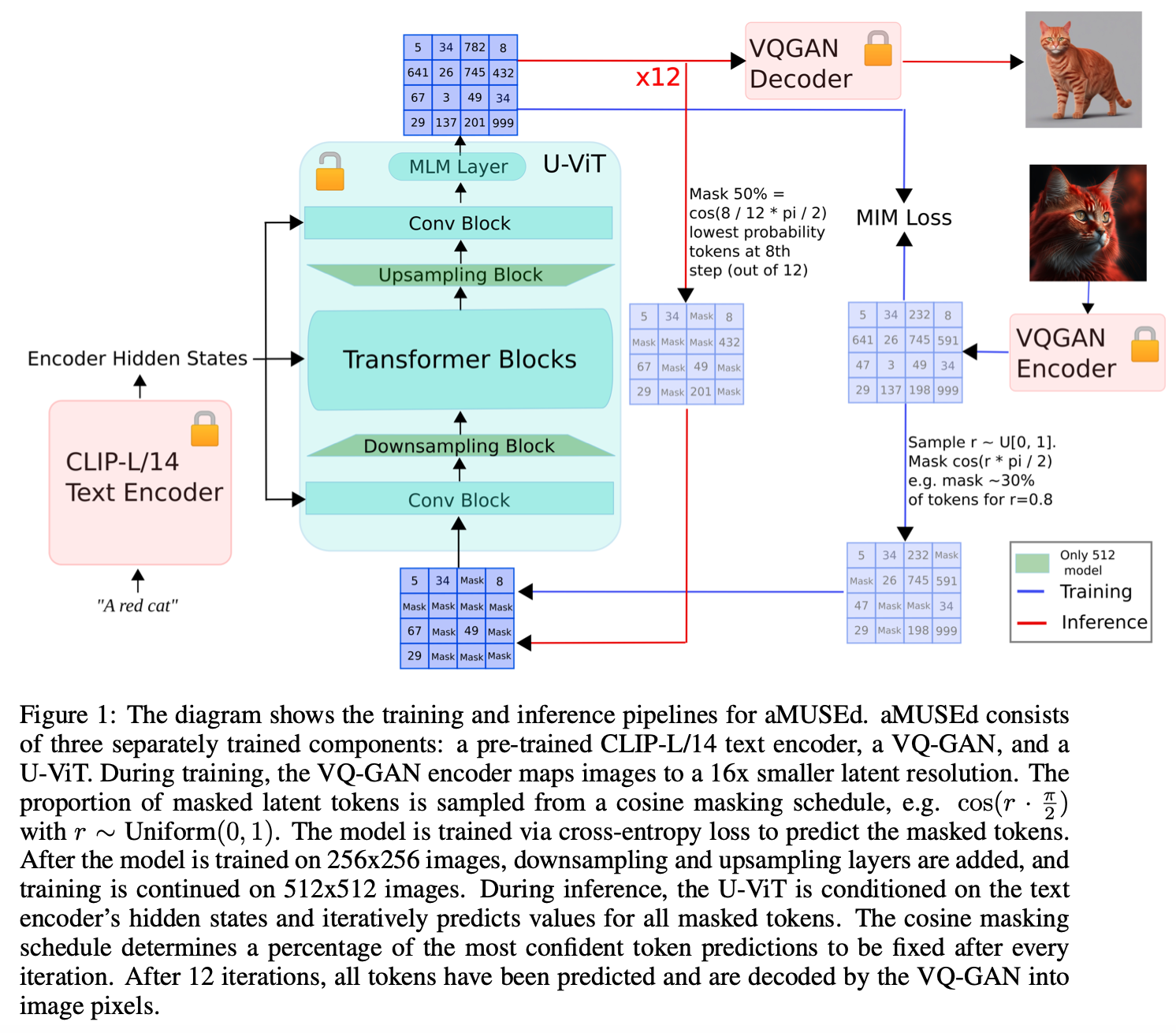
The development of aMUSEd represents a notable stride forward in generating images from text. Addressing the critical challenge of computational efficiency opens new avenues for applying this technology in more diverse and resource-constrained environments. Its ability to maintain quality while drastically reducing computational demands makes it a model that could inspire future research and development. As we move forward, technologies like aMUSEd could redefine the boundaries of creativity, blending the realms of language and imagery in ways previously unimagined.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
[ad_2]
Source link