[ad_1]
Integrating two-dimensional (2D) and three-dimensional (3D) data is a significant challenge. Models tailored for 2D images, such as those based on convolutional neural networks, need to be revised for interpreting complex 3D environments. Models designed for 3D spatial data, like point cloud processors, often fail to effectively leverage the rich detail available in 2D imagery. This disparity in data processing approaches has been a notable bottleneck in creating comprehensive visual understanding systems.
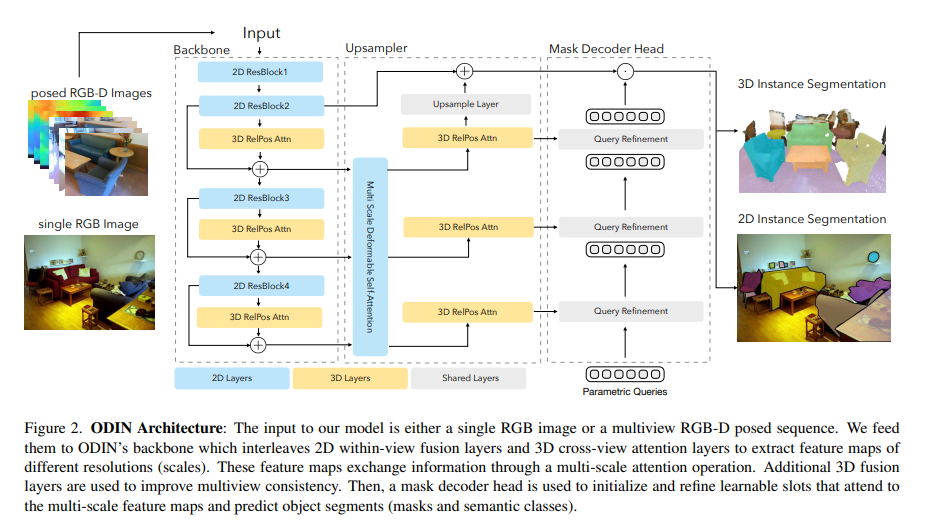
A team of researchers from Carnegie Mellon University, Stanford University, and Microsoft introduced ODIN (Omni-Dimensional INstance segmentation), a transformative model that efficiently processes 2D images and 3D point clouds. This unique framework marks a significant departure from traditional methods that separately treat 2D and 3D data. ODIN’s architecture is built around a transformer model alternating between processing 2D within-view information and 3D cross-view information. This innovative approach enables the model to integrate the two data types seamlessly, enhancing its ability to interpret and interact with complex environments.
The core of ODIN’s methodology lies in its ability to distinguish between 2D and 3D features through specialized positional encodings. For 2D data, it employs pixel coordinates, while for 3D data, it uses XYZ coordinates. This distinction allows ODIN to segment and label objects across both dimensions accurately. Its transformer-based architecture ensures a fluid transition between these two modes of operation, enabling it to handle multiview RGB-D images effectively. By doing so, ODIN leverages the strengths of 2D image processing and 3D spatial data analysis.
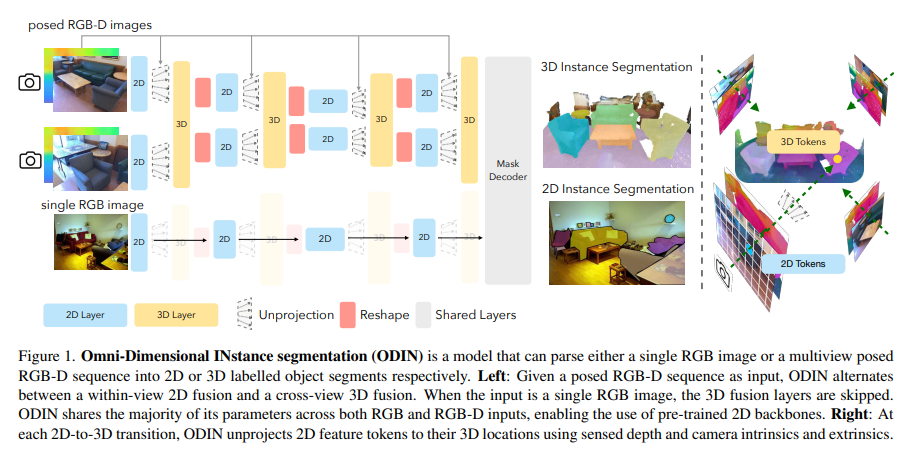
ODIN performs state-of-the-art 3D instance segmentation on ScanNet200, Matterport3D, and AI2THOR benchmarks. Its ability to significantly outperform previous models when utilizing sensed 3D point clouds instead of relying on post-processed data is particularly notable. This indicates a substantial improvement in handling real-world data, which is often noisy and unstructured.
Further enhancing its capability, ODIN’s application in instructable embodied agent architectures sets new standards on the TEACh action-from-dialogue benchmark. This showcases its potential in real-time applications where understanding and interacting with dynamic environments is crucial.
In summary, the research can be presented in a nutshell as follows:
- ODIN bridges the gap between 2D and 3D data processing in computer vision, presenting a unified model for handling both data types.
- It employs a transformer architecture alternating between 2D and 3D information processing, using specialized positional encodings for each data type.
- The model achieves state-of-the-art performance in various 3D instance segmentation benchmarks, outperforming models that rely on post-processed 3D point clouds.
- Its effectiveness in real-world applications is highlighted by its success in instructable embodied agent architectures, setting new standards in benchmarks like TEACh.
- ODIN’s approach marks a significant advancement in computer vision, offering new possibilities for applications requiring detailed environmental understanding.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
[ad_2]
Source link