
[ad_1]
Promotional Content
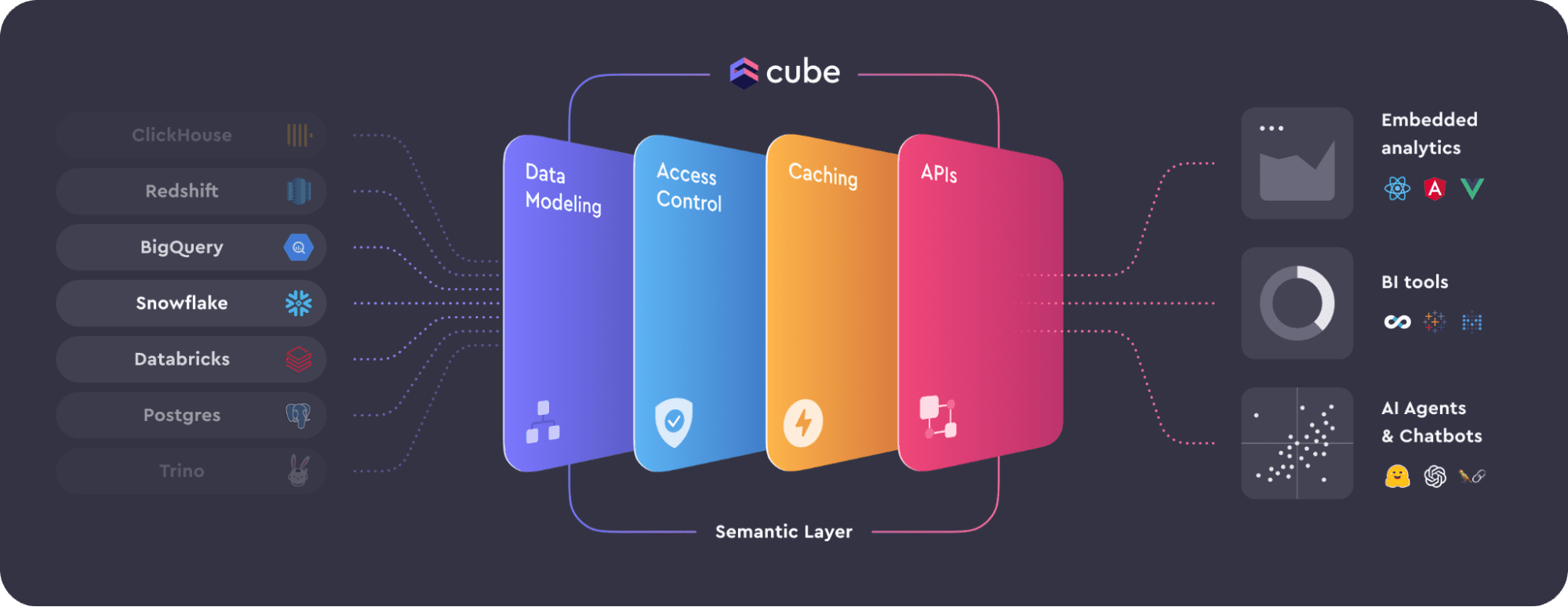
On a daily basis data teams and product managers wrangle the modern data stack in an effort to seamlessly integrate diverse data sources and tools into a cohesive, versatile, and future-proof architecture that end users can easily use.. This is where the semantic layer steps in – an essential middleware that acts as a bridge between data sources and analytical tools, addressing the complexities of the modern data landscape.
What is a Semantic Layer?
A semantic layer acts as a contextual filter, abstracting raw data and presenting it meaningfully to end-users. It contains pre-defined business rules, data definitions, and metadata, standardizing the vocabulary across reporting tools and sources. Cube emphasizes the importance of a “complete, universal semantic layer,” featuring four crucial layers:
The Four Layers of a Semantic Layer
- Data Modeling: Organizes data with meaningful context, ensuring consistent insights and metrics across applications in one location, not every standalone piece of technology.
- Data Access Control: Orchestrates consistent security context upstream, controlling data access for authorized users in one location.
- Caching: Acts as a buffer, optimizing performance by storing data and avoiding redundant queries, reducing the cost of queries while speeding up performance.
- APIs: Ensures compatibility between diverse data sources and downstream applications.
Why Your Data Stack Needs a Semantic Layer
- Data Consistency Ensures a standardized approach to handling data, promoting seamless integration and efficient analysis.
- Data Security: Centralized control of access reduces the risk of breaches and ensures compliance with data privacy regulations.
- Data Performance: Caching layer optimizes response times, crucial for real-time processing and AI applications.
- Stack Flexibility: Enables the selection of tools without sacrificing innovation, thanks to the abstraction of data logic.
- Time-to-Market: Dramatically reduces time spent by developers when creating or maintaining data apps and data models.
- Future Proofing: Adapts to changing business requirements and new data sources, ensuring long-term agility and intelligence.
Use Cases of a Semantic Layer
- Embedded Analytics: Speeds up the development of apps from months to days. Resolves cross-stack incompatibility, enabling custom data experiences and boosting application performance.
- Semantic Layer for BI: Streamlines data orchestration, saving time for data engineers and ensuring consistent insights and metrics across BI tools.
- AI & LLM-based Applications: Facilitates easy integration of proprietary data with AI, simplifying complex joins and enhancing query response times.
In summary, semantic layers provide the context and structure needed to understand data. A stand-alone semantic layer can improve developer workflow, reduce data warehouse cost, improve speed time to market for data app development and make your entire company better able to gather insights from data.
Cube is highlighted in the GigaOm Sonar Report as a Leader and Fast Mover. They noted Cube’s strengths to include strong code-first orientation, native API support, and its analytics pre-processing through caching and pre-aggregations.
[ad_2]
Source link

