[ad_1]
The struggle to balance training efficiency with performance has become increasingly pronounced within computer vision. Traditional training methodologies, often reliant on expansive datasets, substantially burden computational resources, creating a notable barrier for researchers with limited access to high-powered computing infrastructures. This issue is compounded by the fact that many existing solutions, while reducing the sample size for training, inadvertently introduce additional overheads or fail to maintain the model’s original performance level, thus negating the benefits of their implementation.
Central to this challenge is the quest to optimize the training of deep learning models, a task that is as resource-intensive as it is crucial. The primary obstacle is the computational demand of training on extensive datasets without compromising the model’s effectiveness. This has emerged as a vital concern in the field, where efficiency and performance must coexist harmoniously to advance practical and accessible machine learning applications.
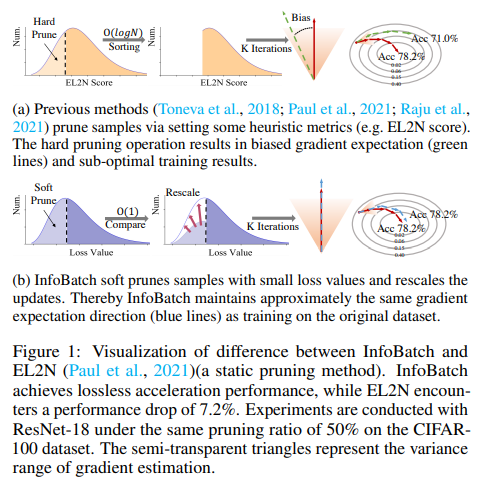
The existing solutions landscape includes methods like dataset distillation and corset selection, both aimed at reducing the training sample size. While these approaches are intuitively appealing, they introduce new complexities. Static pruning methods, for example, which select samples based on specific metrics before training, often incur additional computational costs and need help with generalizability across various architectures or datasets. On the other hand, dynamic data pruning methods aim to cut training costs by decreasing the number of iterations. However, these methods have limitations, primarily in achieving lossless results and operational efficiency.
The National University of Singapore and Alibaba Group researchers introduced InfoBatch, an innovative framework designed to accelerate training without sacrificing accuracy. InfoBatch distinguishes itself from previous methodologies through its dynamic approach to data pruning, which is unbiased and adaptable. It maintains and dynamically updates a loss-based score for each data sample throughout the training process. The framework then selectively prunes less informative samples, identified by their low score, and compensates for this pruning by scaling up the gradients of the remaining samples. This strategy effectively maintains a gradient expectation similar to the original, unpruned dataset, thereby preserving the model’s performance.
The framework has demonstrated its capability to significantly reduce computational overhead, outperforming previous state-of-the-art methods by at least tenfold in efficiency. This efficiency gain does not come at the cost of performance; InfoBatch consistently achieves lossless training results across various tasks, including classification, semantic segmentation, vision pertaining, and fine-tuning language model instruction. In practical terms, this translates to substantial cost savings in computational resources and time. For instance, when applied to datasets like CIFAR10/100 and ImageNet1K, InfoBatch has been shown to save up to 40% of the overall cost. Even more impressively, the cost savings climb to 24.8% and 27% for specific models such as MAE and diffusion models.
To summarize, the key takeaways from the InfoBatch research include:
- InfoBatch introduces a novel framework for unbiased dynamic data pruning, setting it apart from traditional static and dynamic pruning methods.
- The framework dramatically reduces the computational overhead, making it practical for real-world applications, especially those with limited computational resources.
- Despite the efficiency improvements, InfoBatch consistently achieves lossless training results across various tasks.
- The framework’s versatility is demonstrated through its effective application in diverse machine learning tasks, from classification to language model instruction fine-tuning.
- InfoBatch’s balance of efficiency and performance can significantly influence the future of machine learning training methodologies.
In conclusion, the development of InfoBatch represents a significant stride forward in machine learning, offering a practical solution to a longstanding challenge in the field. By efficiently balancing training costs with model performance, InfoBatch stands as a testament to the innovative progress in computational efficiency in machine learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
[ad_2]
Source link