[ad_1]
Mathematical reasoning, part of our advanced thinking, reveals the complexities of human intelligence. It involves logical thinking and specialized knowledge, not just in words but also in pictures, crucial for understanding abilities. This has practical uses in AI. However, current AI datasets often focus narrowly, missing a full exploration of combining visual language understanding with math.
While Large Language Models (LLMs) and Large Multimodal Models (LMMs) demonstrate remarkable problem-solving abilities across diverse tasks, their aptitude for mathematical reasoning in visual contexts remains understudied. To address this gap, researchers from UCLA, the University of Washington, and Microsoft introduce MATHVISTA, a benchmark that amalgamates challenges from various mathematical and visual tasks. This benchmark comprises 6,141 examples sourced from 28 existing multimodal datasets related to mathematics and three newly developed datasets (IQTest, FunctionQA, and PaperQA). Successful completion of these tasks necessitates nuanced visual understanding and intricate compositional reasoning, posing difficulties even for the most advanced foundation models.
In this paper, the authors introduce MATHVISTA, a comprehensive benchmark for mathematical reasoning in visual contexts. They propose a task taxonomy to guide its development, identifying seven types of mathematical reasoning and focusing on five primary tasks: figure question answering (FQA), geometry problem solving (GPS), math word problem (MWP), textbook question answering (TQA), and visual question answering (VQA). The benchmark encompasses a diverse range of visual contexts, such as natural images, geometry diagrams, abstract scenes, synthetic scenes, figures, charts, and plots. MATHVISTA incorporates 28 existing multimodal datasets, comprising 9 math-targeted question-answering (MathQA) datasets and 19 VQA datasets.
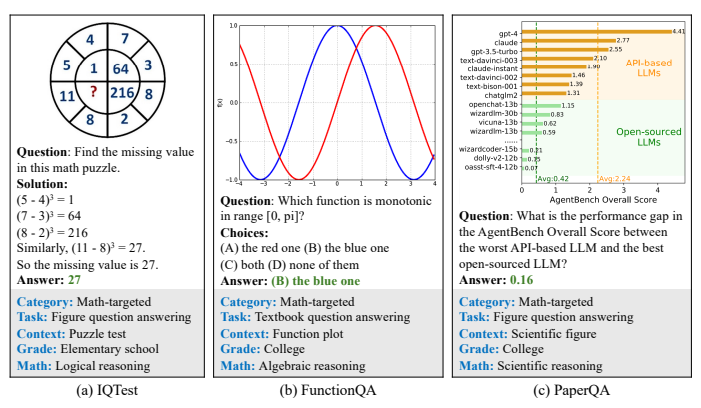
Researchers extensively tested 12 leading foundation models, including three Large Language Models (LLMs) such as ChatGPT, GPT-4, Claude-2, two proprietary Large Multimodal Models (LMMs) – GPT4V, Bard, and seven open-source LMMs. They evaluated these models on MATHVISTA, employing zero-shot and few-shot settings with chain-of-thought (CoT) and program-of-thought (PoT) prompting strategies. The above figure demonstrates examples of the newly annotated datasets: IQTest, FunctionQA, and PaperQA.
The findings reveal that CoT GPT-4, the best-performing text-based model without visual enhancements, achieves an overall accuracy of 29.2%. In comparison, the best-performing multimodal model, Bard, achieves 34.8%, representing 58% of human performance (34.8% vs. 60.3%). When PoT GPT-4 is enhanced with Bard captions and OCR text, it reaches 33.9%, closely matching the Multimodal Bard.
Further analysis suggests that Bard’s model shortcomings stem from incorrect calculations and hallucinations influenced by visual perception and textual reasoning. Notably, GPT-4V, the latest multimodal version of GPT-4, achieves a state-of-the-art accuracy of 49.9%, a significant 15.1% improvement over Multimodal Bard, as reported in the first comprehensive evaluation using MATHVISTA. As the field continues to advance, their work contributes valuable insights for further refining mathematical reasoning in multimodal AI systems!
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.

[ad_2]
Source link