
[ad_1]
We live in an era where the machine learning model is at its peak. Compared to decades ago, most people would never have heard about ChatGPT or Artificial Intelligence. However, those are the topics that people keep talking about. Why? Because the values given are so significant compared to the effort.
The breakthrough of AI in recent years could be attributed to many things, but one of them is the large language model (LLM). Many text generation AI people use are powered by the LLM model; For example, ChatGPT uses their GPT model. As LLM is an important topic, we should learn about it.
This article will discuss Large Language Models in 3 difficulty levels, but we will only touch on some aspects of LLMs. We would only differ in a way that allows every reader to understand what LLM is. With that in mind, let’s get into it.
In the first level, we assume the reader doesn’t know about LLM and may know a little about the field of data science/machine learning. So, I would briefly introduce AI and Machine Learning before moving to the LLMs.
Artificial Intelligence is the science of developing intelligent computer programs. It’s intended for the program to perform intelligent tasks that humans could do but does not have limitations on human biological needs. Machine learning is a field in artificial intelligence focusing on data generalization studies with statistical algorithms. In a way, Machine Learning is trying to achieve Artificial Intelligence via data study so that the program can perform intelligence tasks without instruction.
Historically, the field that intersects between computer science and linguistics is called the Natural Language Processing field. The field mainly concerns any activity of machine processing to the human text, such as text documents. Previously, this field was only limited to the rule-based system but it became more with the introduction of advanced semi-supervised and unsupervised algorithms that allow the model to learn without any direction. One of the advanced models to do this is the Language Model.
The language model is a probabilistic NLP model to perform many human tasks such as translation, grammar correction, and text generation. The old form of the language model uses purely statistical approaches such as the n-gram method, where the assumption is that the probability of the next word depends only on the previous word’s fixed-size data.
However, the introduction of Neural Network has dethroned the previous approach. An artificial neural network, or NN, is a computer program mimicking the human brain’s neuron structure. The Neural Network approach is good to use because it can handle complex pattern recognition from the text data and handle sequential data like text. That’s why the current Language Model is usually based on NN.
Large Language Models, or LLMs, are machine learning models that learn from a huge number of data documents to perform general-purpose language generation. They are still a language model, but the huge number of parameters learned by the NN makes them considered large. In layperson’s terms, the model could perform how humans write by predicting the next words from the given input words very well.
Examples of LLM tasks include language translation, machine chatbot, question answering, and many more. From any sequence of data input, the model could identify relationships between the words and generate output suitable from the instruction.
Almost all of the Generative AI products that boast something using text generation are powered by the LLMs. Big products like ChatGPT, Google’s Bard, and many more are using LLMs as the basis of their product.
The reader has data science knowledge but needs to learn more about the LLM at this level. At the very least, the reader can understand the terms used in the data field. At this level, we would dive deeper into the base architecture.
As explained previously, LLM is a Neural Network model trained on massive amounts of text data. To understand this concept further, it would be beneficial to understand how neural networks and deep learning work.
In the previous level, we explained that a neural neuron is a model miming the human brain’s neural structure. The main element of the Neural Network is the neurons, often called nodes. To explain the concept better, see the typical Neural Network architecture in the image below.
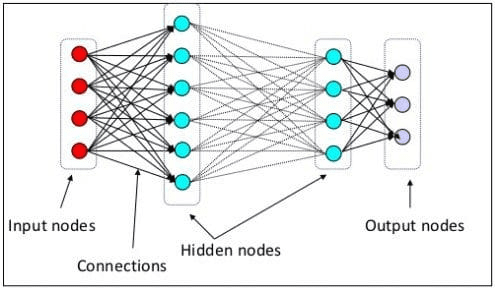
Neural Network Architecture(Image source: KDnuggets)
As we can see in the image above, the Neural Network consists of three layers:
- Input layer where it receives the information and transfers it to the other nodes in the next layer.
- Hidden node layers where all the computations take place.
- Output node layer where the computational outputs are.
It’s called deep learning when we train our Neural Network model with two or more hidden layers. It’s called deep because it uses many layers in between. The advantage of deep learning models is that they automatically learn and extract features from the data that traditional machine learning models are incapable of.
In the Large Language Model, deep learning is important as the model is built upon deep neural network architectures. So, why is it called LLM? It’s because billions of layers are trained upon massive amounts of text data. The layers would produce model parameters that help the model learn complex patterns in language, including grammar, writing style, and many more.
The simplified process of the model training is shown in the image below.
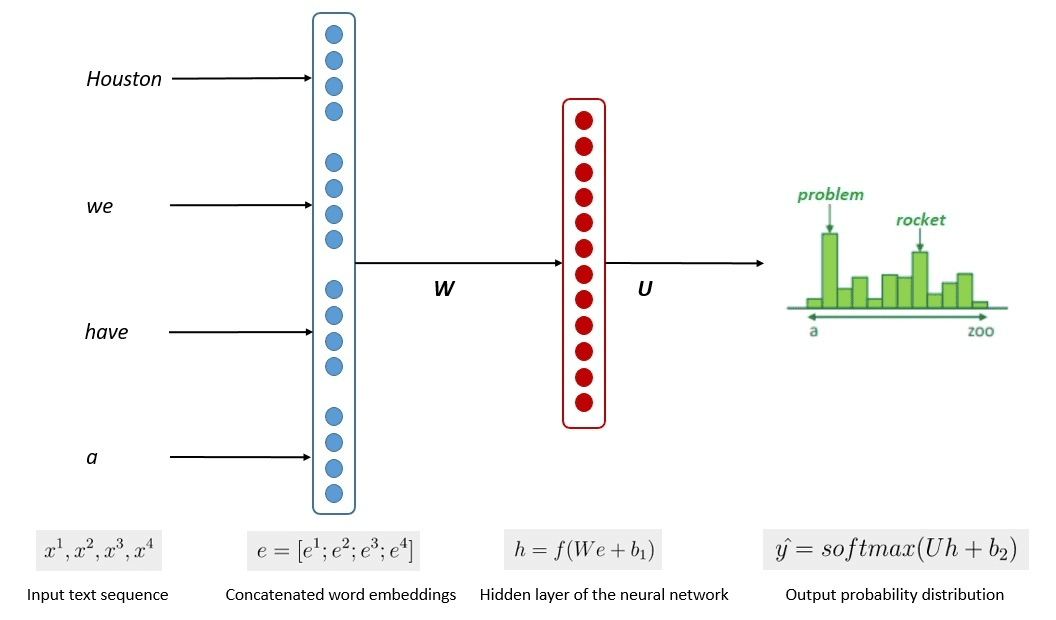
Image by Kumar Chandrakant (Source: Baeldung.com)
The process showed that the models could generate relevant text based on the likelihood of each word or sentence of the input data. In the LLMs, the advanced approach uses self-supervised learning and semi-supervised learning to achieve the general-purpose capability.
Self-supervised learning is a technique where we don’t have labels, and instead, the training data provides the training feedback itself. It’s used in the LLM training process as the data usually lacks labels. In LLM, one could use the surrounding context as a clue to predict the next words. In contrast, Semi-supervised learning combines the supervised and unsupervised learning concepts with a small amount of labeled data to generate new labels for a large amount of unlabeled data. Semi-supervised learning is usually used for LLMs with specific context or domain needs.
In the third level, we would discuss the LLM more deeply, especially tackling the LLM structure and how it could achieve human-like generation capability.
We have discussed that LLM is based on the Neural Network model with Deep Learning techniques. The LLM has typically been built based on transformer-based architecture in recent years. The transformer is based on the multi-head attention mechanism introduced by Vaswani et al. (2017) and has been used in many LLMs.
Transformers is a model architecture that tries to solve the sequential tasks previously encountered in the RNNs and LSTMs. The old way of the Language Model was to use RNN and LSTM to process data sequentially, where the model would use every word output and loop them back so the model would not forget. However, they have problems with long-sequence data once transformers are introduced.
Before we go deeper into the Transformers, I want to introduce the concept of encoder-decoder that was previously used in RNNs. The encoder-decoder structure allows the input and output text to not be of the same length. The example use case is a language translation, which often has a different sequence size.
The structure can be divided into two. The first part is called Encoder, which is a part that receives data sequence and creates a new representation based on it. The representation would be used in the second part of the model, which is the decoder.
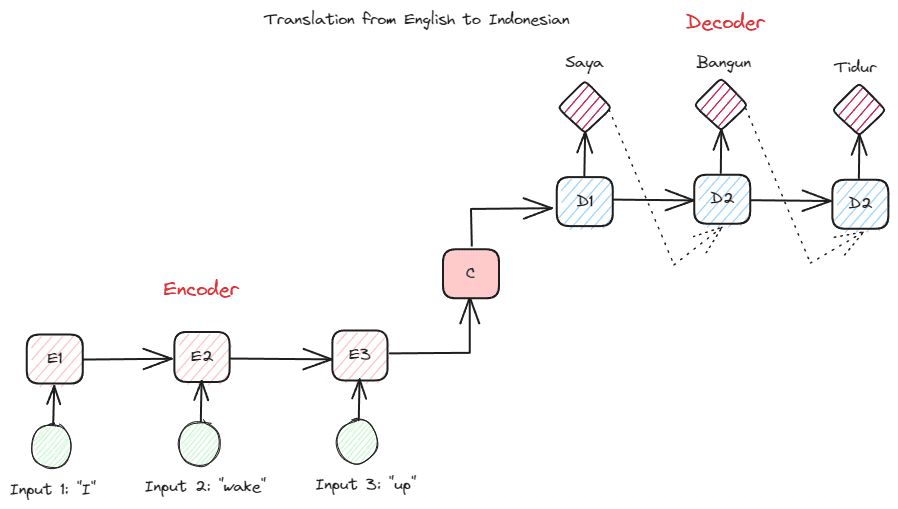
Image by Author
The problem with RNN is that the model might need help remembering longer sequences, even with the encoder-decoder structure above. This is where the attention mechanism could help solve the problem, a layer that could solve long input problems. The attention mechanism is introduced in the paper by Bahdanau et al. (2014) to solve the encoder-decoder type RNNs by focusing on an important part of the model input while having the output prediction.
The transformer’s structure is inspired by the encoder-decoder type and built with the attention mechanism techniques, so it does not need to process data in sequential order. The overall transformers model is structured like the image below.
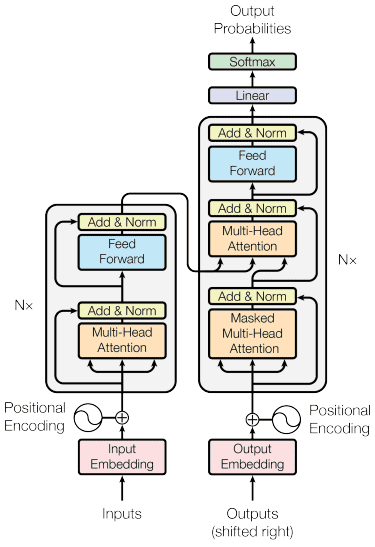
Transformers Architecture (Vaswani et al. (2017))
In the structure above, the transformers encode the data vector sequence into the word embedding while using the decoding to transform data into the original form. The encoding can assign a certain importance to the input with the attention mechanism.
We have talked a bit about transformers encoding the data vector, but what is a data vector? Let’s discuss it. In the machine learning model, we can’t input the raw natural language data into the model, so we need to transform them into numerical forms. The transformation process is called word embedding, where each input word is processed through the word embedding model to get the data vector. We can use many initial word embeddings, such as Word2vec or GloVe, but many advanced users try to refine them using their vocabulary. In a basic form, the word embedding process can be shown in the image below.
Image by Author
The transformers could accept the input and provide more relevant context by presenting the words in numerical forms like the data vector above. In the LLMs, word embeddings are usually context-dependent, generally refined upon the use cases and the intended output.
We discussed the Large Language Model in three difficulty levels, from beginner to advanced. From the general usage of LLM to how it is structured, you can find an explanation that explains the concept in more detail.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.
[ad_2]
Source link

