[ad_1]
In recent years, LMMs have rapidly expanded, leveraging CLIP as a foundational vision encoder for robust visual representations and LLMs as versatile tools for reasoning across various modalities. However, while LLMs have grown to over 100 billion parameters, the vision models they rely on need to be bigger, hindering their potential. Scaling up contrastive language-image pretraining (CLIP) is essential to enhance both vision and multimodal models, bridging the gap and enabling more effective handling of diverse data types.
Researchers from the Beijing Academy of Artificial Intelligence and Tsinghua University have unveiled EVA-CLIP-18B, the largest open-source CLIP model yet, boasting 18 billion parameters. Despite training on just 6 billion samples, it achieves an impressive 80.7% zero-shot top-1 accuracy across 27 image classification benchmarks, surpassing prior models like EVA-CLIP. Notably, this advancement is achieved with a modest dataset of 2 billion image-text pairs, openly available and smaller than those used in other models. EVA-CLIP-18B showcases the potential of EVA-style weak-to-strong visual model scaling, with hopes of fostering further research in vision and multimodal foundation models.
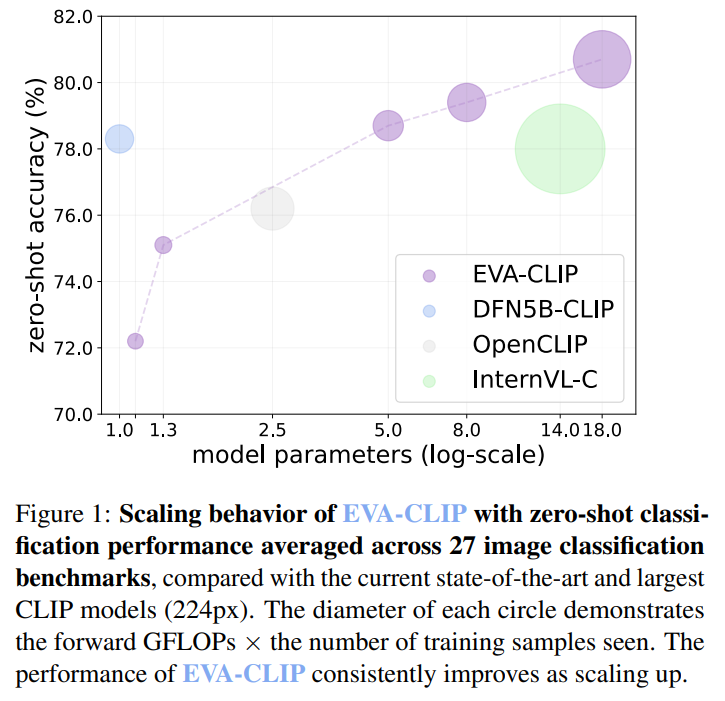
EVA-CLIP-18B is the largest and most powerful open-source CLIP model, with 18 billion parameters. It outperforms its predecessor EVA-CLIP (5 billion parameters) and other open-source CLIP models by a large margin in terms of zero-shot top-1 accuracy on 27 image classification benchmarks. The principles of EVA and EVA-CLIP guide the scaling-up procedure of EVA-CLIP-18B. The EVA philosophy follows a weak-to-strong paradigm, where a small EVA-CLIP model serves as the vision encoder initialization for a larger EVA-CLIP model. This iterative scaling process stabilizes and accelerates the training of larger models.
EVA-CLIP-18B, an 18-billion-parameter CLIP model, is trained on a 2 billion image-text pairs dataset from LAION-2B and COYO-700M. Following the EVA and EVA-CLIP principles, it employs a weak-to-strong paradigm, where a smaller EVA-CLIP model initializes a larger one, stabilizing and expediting training. Evaluation across 33 datasets, including image and video classification and image-text retrieval, demonstrates its efficacy. The scaling process involves distilling knowledge from a small EVA-CLIP model to a larger EVA-CLIP, with the training dataset mostly fixed to showcase the effectiveness of the scaling philosophy. Notably, the approach yields sustained performance gains, exemplifying the effectiveness of progressive weak-to-strong scaling.
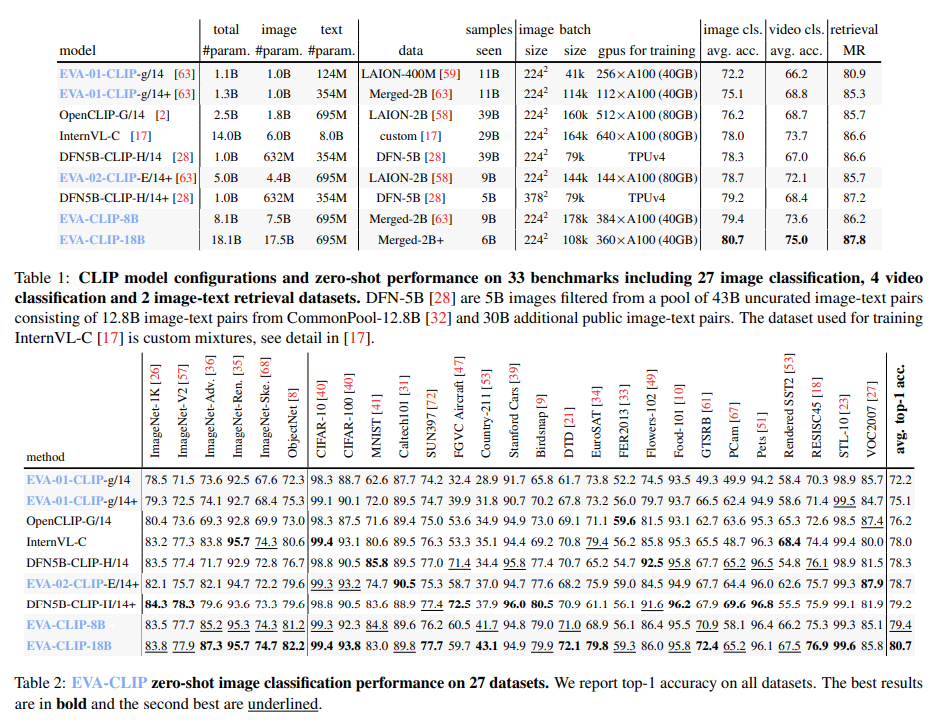
EVA-CLIP-18B, boasting 18 billion parameters, showcases outstanding performance across various image-related tasks. It achieves an impressive 80.7% zero-shot top-1 accuracy across 27 image classification benchmarks, surpassing its predecessor and other CLIP models by a significant margin. Moreover, linear probing on ImageNet-1K outperforms competitors like InternVL-C with an average top-1 accuracy of 88.9. Zero-shot image-text retrieval on Flickr30K and COCO datasets achieves an average recall of 87.8, significantly surpassing competitors. EVA-CLIP-18B exhibits robustness across different ImageNet variants, demonstrating its versatility and high performance across 33 widely used datasets.
In conclusion, EVA-CLIP-18B is the largest and highest-performing open-source CLIP model, boasting 18 billion parameters. Applying EVA’s weak-to-strong vision scaling principle achieves exceptional zero-shot top-1 accuracy across 27 image classification benchmarks. This scaling approach consistently improves performance without reaching saturation, pushing the boundaries of vision model capabilities. Notably, EVA-CLIP-18B exhibits robustness in visual representations, maintaining performance across various ImageNet variants, including adversarial ones. Its versatility and effectiveness are demonstrated across multiple datasets, spanning image classification, image-text retrieval, and video classification tasks, marking a significant advancement in CLIP model capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
[ad_2]
Source link