[ad_1]
Multimodal architectures are revolutionizing the way systems process and interpret complex data. These advanced architectures facilitate simultaneous analysis of diverse data types such as text and images, broadening AI’s capabilities to mirror human cognitive functions more accurately. The seamless integration of these modalities is crucial for developing more intuitive and responsive AI systems that can perform various tasks more effectively.
A persistent challenge in the field is the efficient and coherent fusion of textual and visual information within AI models. Despite numerous advancements, many systems face difficulties aligning and integrating these data types, resulting in suboptimal performance, particularly in tasks that require complex data interpretation and real-time decision-making. This gap underscores the critical need for innovative architectural solutions to bridge these modalities more effectively.
Multimodal AI systems have incorporated large language models (LLMs) with various adapters or encoders specifically designed for visual data processing. These systems are geared towards enhancing the AI’s capability to process and understand images in conjunction with textual inputs. However, they often do not achieve the desired level of integration, leading to inconsistencies and inefficiencies in how the models handle multimodal data.
Researchers from AIRI, Sber AI, and Skoltech have proposed an OmniFusion model relying on a pretrained LLM and adapters for visual modality. This innovative multimodal architecture synergizes the robust capabilities of pre-trained LLMs with cutting-edge adapters designed to optimize visual data integration. OmniFusion utilizes an array of advanced adapters and visual encoders, including CLIP ViT and SigLIP, aiming to refine the interaction between text and images and achieve a more integrated and effective processing system.
OmniFusion introduces a versatile approach to image encoding by employing both whole and tiled image encoding methods. This adaptability allows for an in-depth visual content analysis, facilitating a more nuanced relationship between textual and visual information. The architecture of OmniFusion is designed to experiment with various fusion techniques and architectural configurations to improve the coherence and efficacy of multimodal data processing.
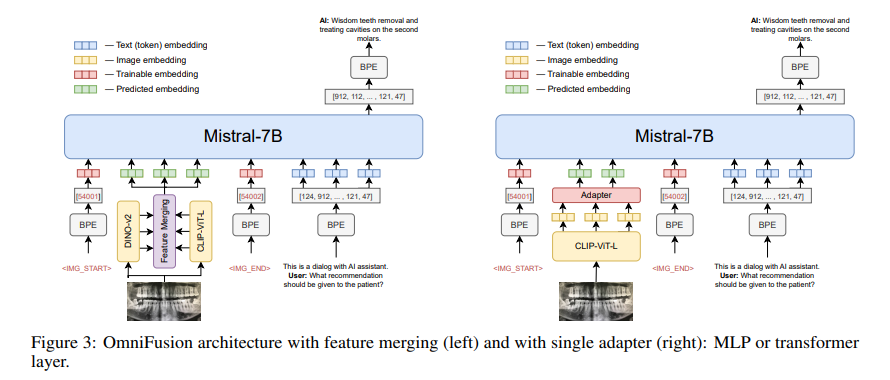
OmniFusion’s performance metrics are particularly impressive in visual question answering (VQA). The model has been rigorously tested across eight visual-language benchmarks, consistently outperforming leading open-source solutions. In the VQAv2 and TextVQA benchmarks, OmniFusion demonstrated superior performance, with scores surpassing existing models. Its success is also evident in domain-specific applications, where it provides accurate and contextually relevant answers in fields such as medicine and culture.
Research Snapshot

In conclusion, OmniFusion addresses the significant challenge of integrating textual and visual data within AI systems, a crucial step for improving performance in complex tasks like visual question answering. By harnessing a novel architecture that merges pre-trained LLMs with specialized adapters and advanced visual encoders, OmniFusion effectively bridges the gap between different data modalities. This innovative approach surpasses existing models in rigorous benchmarks and demonstrates exceptional adaptability and effectiveness across various domains. The success of OmniFusion marks a pivotal advancement in multimodal AI, setting a new benchmark for future developments in the field.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Want to get in front of 1.5 Million AI Audience? Work with us here
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
[ad_2]
Source link