[ad_1]
The field of deep reinforcement learning (DRL) is expanding the capabilities of robotic control. However, there has been a growing trend of increasing algorithm complexity. As a result, the latest algorithms need many implementation details to perform well on different levels, causing issues with reproducibility. Moreover, even state-of-the-art DRL models have simple problems, like the Mountain Car environment or the Swimmer task. However, several works have gone against finding simpler baselines and scalable alternatives for RL tasks, so these efforts emphasized the need for simplicity in the field. Complex RL algorithms often require detailed task design in the form of slow reward engineering.
To address these issues, this paper discusses related works like the quest for simpler RL baselines and Periodic policies for locomotion. In the first approach, simpler parametrizations such as linear function or radial basis functions (RBF) are proposed, highlighting the fragility of RL. The second approach involves periodic policies for locomotion, integrating rhythmic movements into robotic control. Recent work has focused on using oscillators to manage locomotion tasks in quadruped robots. However, no prior studies have examined the application of open-loop oscillators in RL locomotion benchmarks.
Researchers from the German Aerospace Center (DLR) RMC in Germany, Sorbonne Université CNRS in France, and TU Delft CoR in the Netherlands have proposed a simple, open-loop model-free baseline that performs better on standard locomotion tasks without any use of complex models or a lot of computational resources. Although it does not beat RL algorithms in simulation, it provides multiple benefits for real-world applications. These benefits include fast computation, easy deployment on embedded systems, smooth control outputs, and robustness to sensor noise. This method is designed to solve locomotion tasks but is not limited to versatility due to its simplicity.
JAX implementations are used from Stable-Baselines3 and the RL Zoo training framework for the RL baselines. The search space is used to optimize the parameters of the oscillators. The effectiveness of the proposed method is tested on the MuJoCo v4 locomotion tasks included in the Gymnasium v0.29.1 library. The approach is compared against three established deep RL algorithms: (a) Proximal Policy Optimization (PPO), (b) Deep Deterministic Policy Gradients (DDPG), and (c) Soft Actor-Critic (SAC). Further, the hyperparameter settings are obtained from the original papers to ensure a fair comparison, except for the swimmer task, where the discount factor (γ = 0.9999) is fine-tuned.
The proposed baseline and associated experiments highlight the existing limitations of DRL for robotic applications, provide insights on how to address them, and encourage reflection on the costs of complexity and generality. DRL algorithms are compared to the baseline through experiments on locomotion tasks, including simulated tasks, and transfer to a real elastic quadruped. This paper aims to address three key questions:
- How do open-loop oscillators fare against DRL methods in terms of performance, runtime, and parameter efficiency?
- How resilient are RL policies to sensor noise, failures, and external disturbances compared to the open-loop baseline?
- How do learned policies transfer to a real robot when training without randomization or reward engineering?
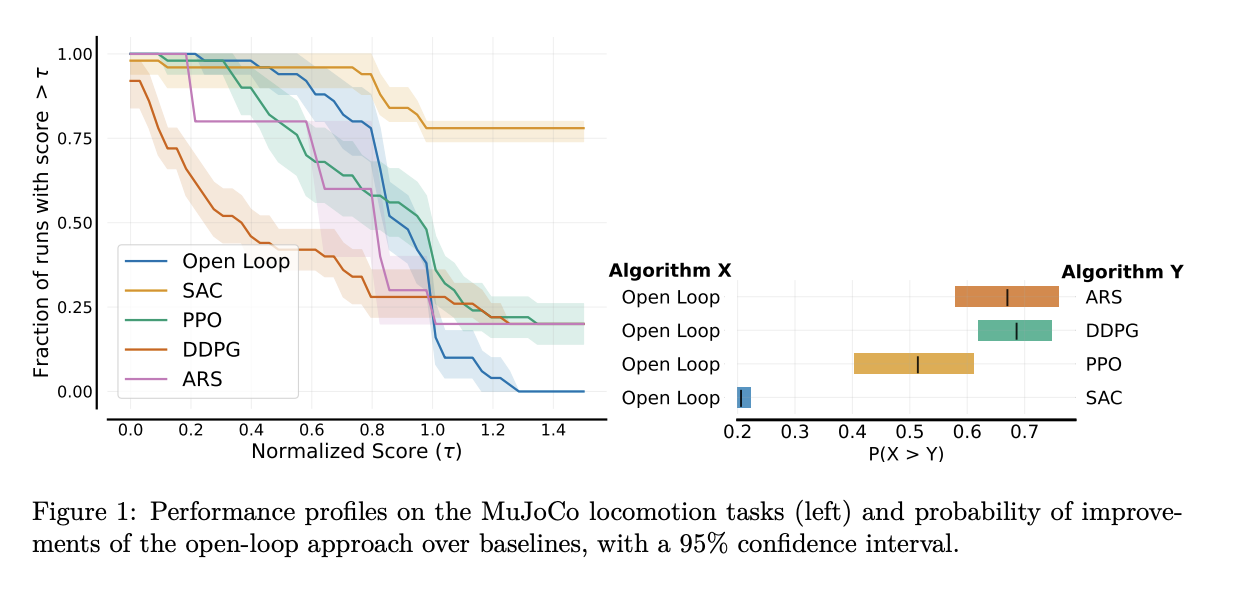
In conclusion, researchers introduced an open-loop model-free baseline that performs well on standard locomotion tasks without needing complex models or computational resources. In this paper, two more experiments are included, which were conducted using open-loop oscillators to detect the current drawback of DRL algorithms. DRL, when compared against the baseline, shows that it is more prone to low performance when faced with sensor noise or failure. However, by design, open-loop control is sensitive to disturbances and cannot recover from potential falls, limiting this baseline. This method produces joint positions without using the robot’s state. So, a PD controller is needed in simulation to transform these positions into torque commands.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
[ad_2]
Source link