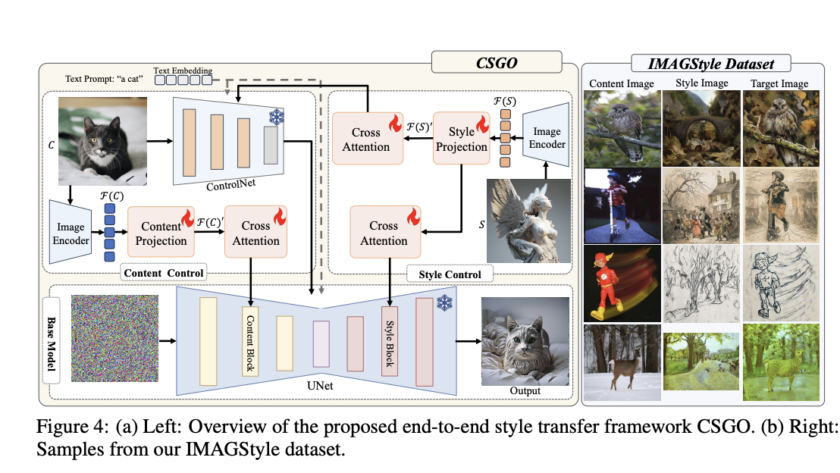
[ad_1]
Text-to-image generation has evolved rapidly, with significant contributions from diffusion models, which have revolutionized the field. These models are designed to produce realistic and detailed images based on textual descriptions, which are vital for applications ranging from personalized content creation to artistic…