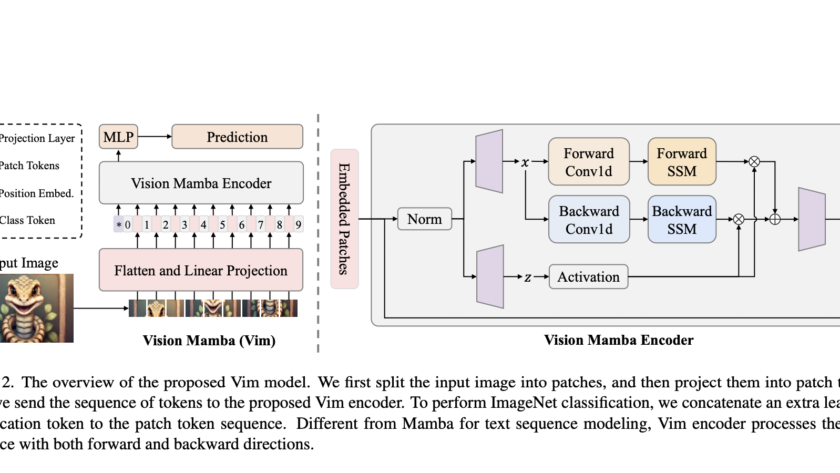
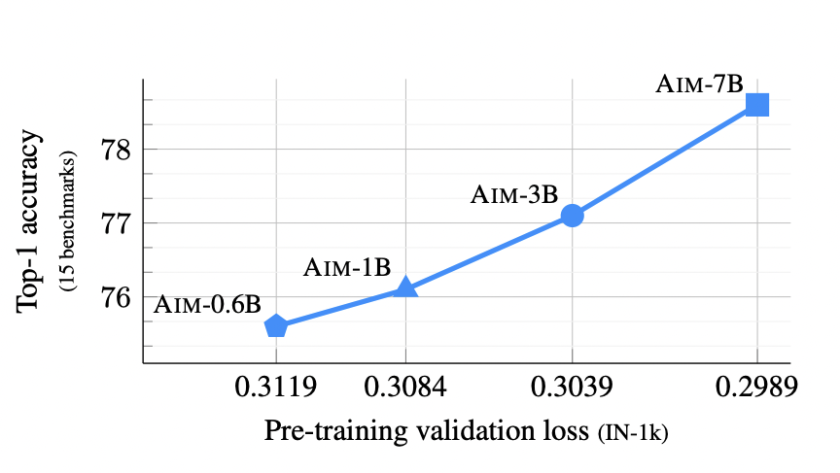
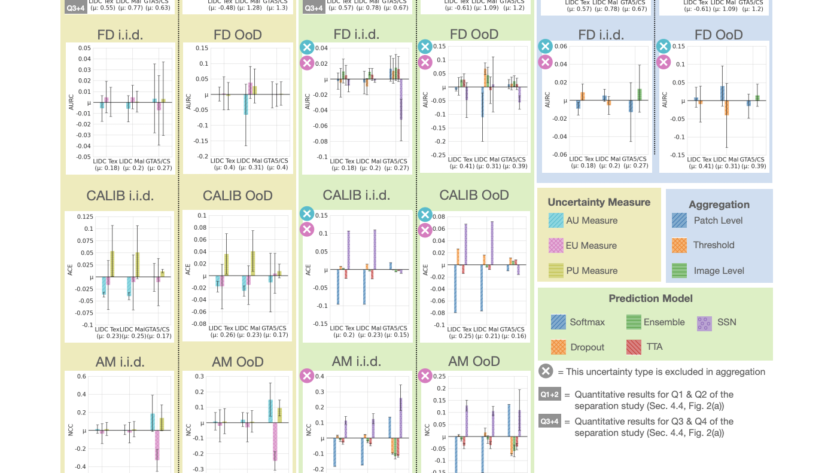
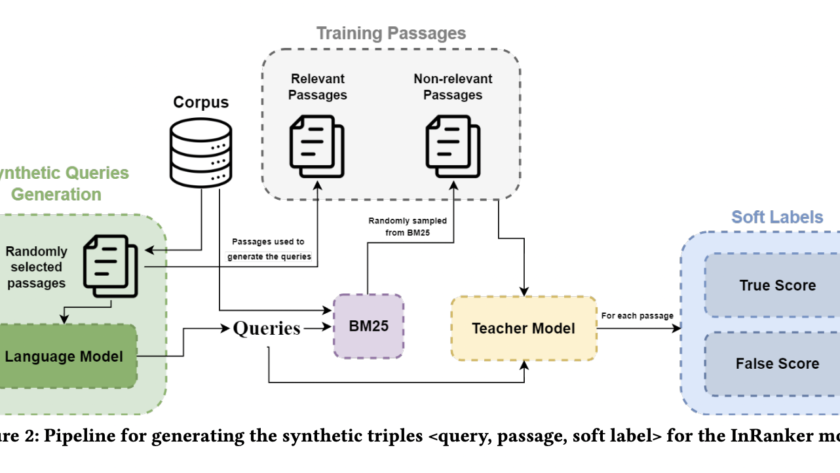
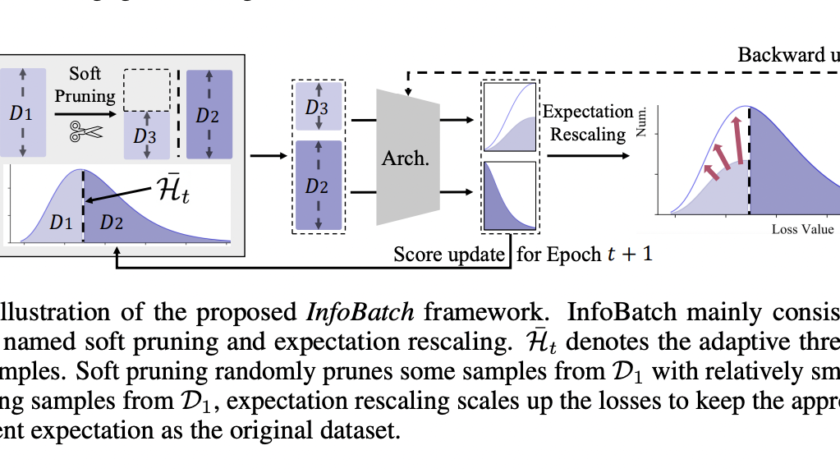
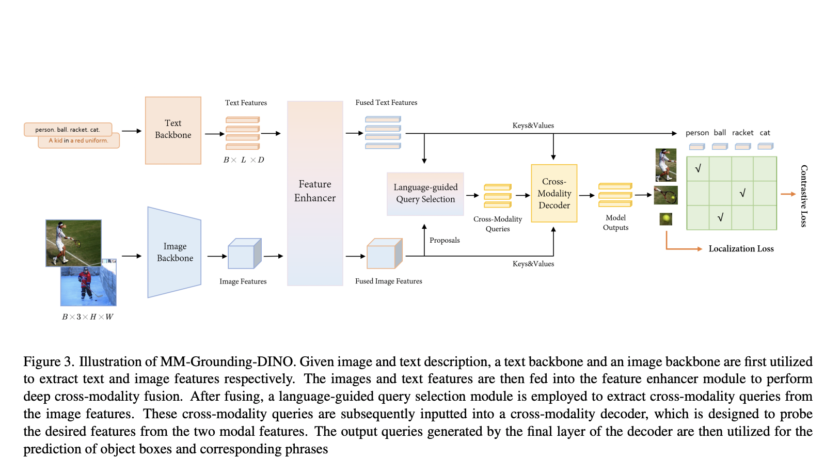
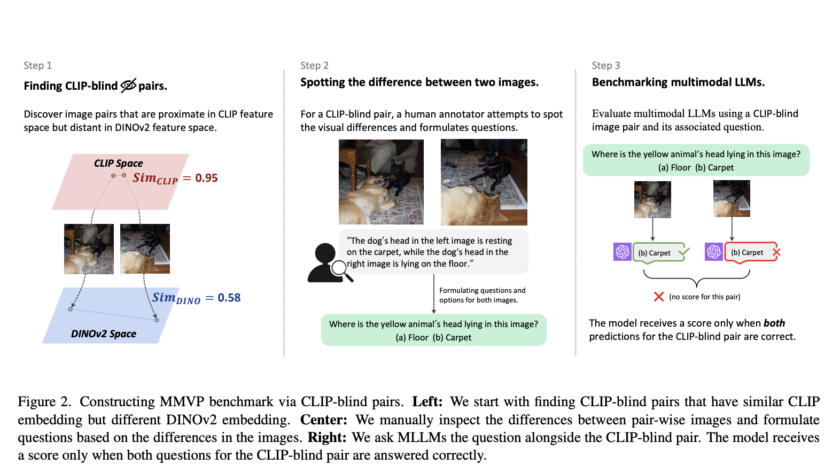
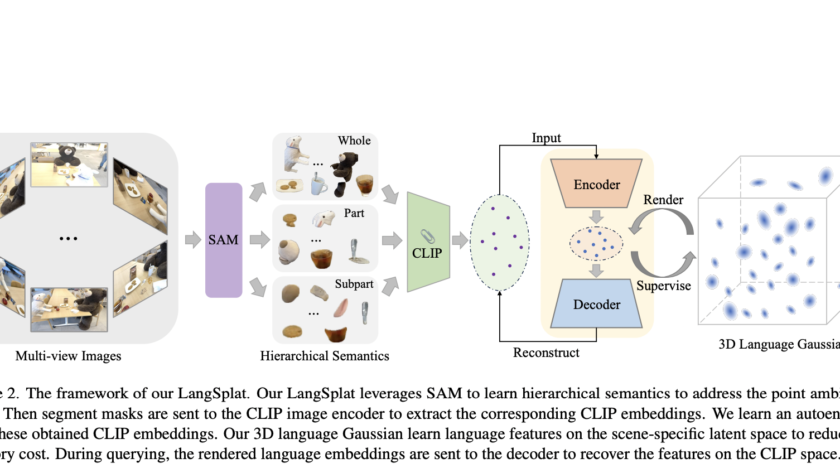
[ad_1]
Many people are now interested in the state space model (SSM) because of how recent research has advanced. Modern SSMs, which derive from the classic state space model, benefit from concurrent training and excel at capturing long-range dependencies. Process sequence data across…