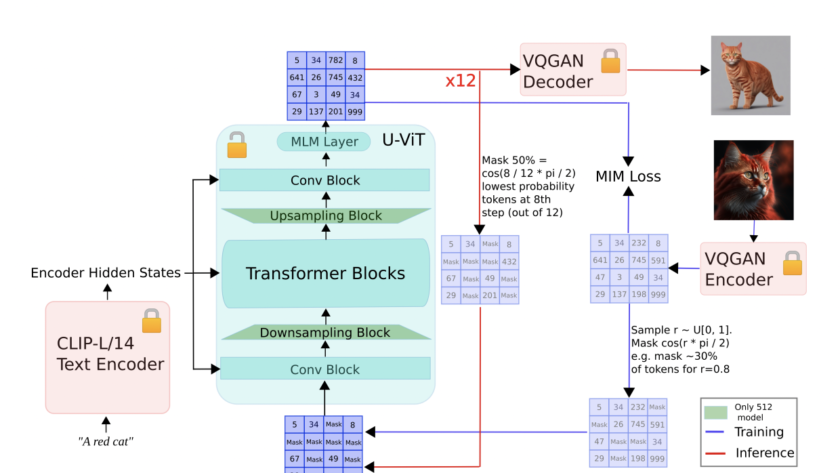
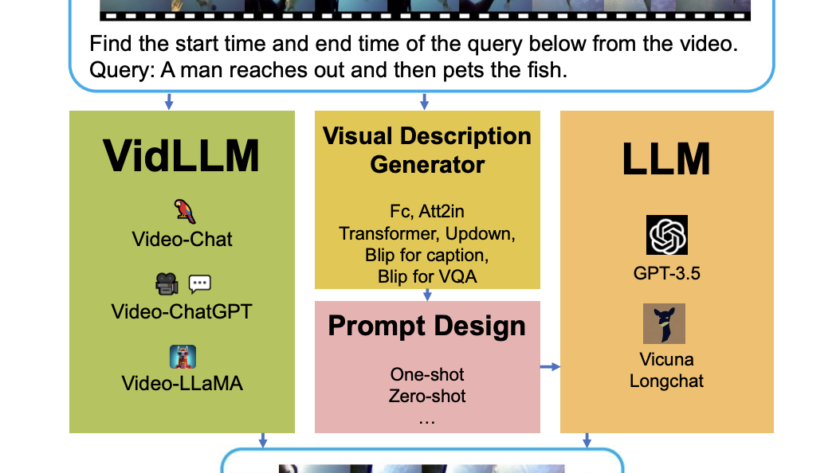
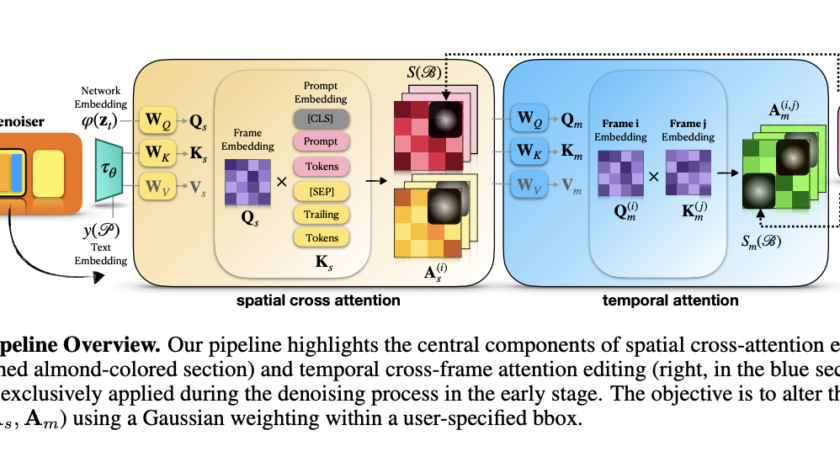
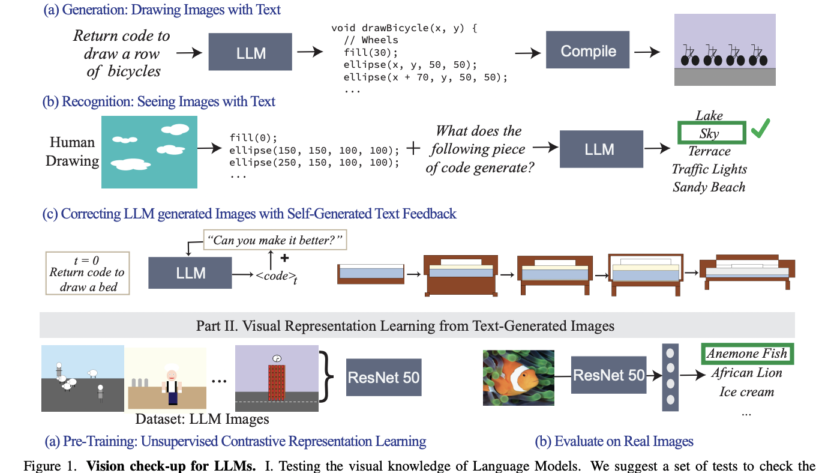
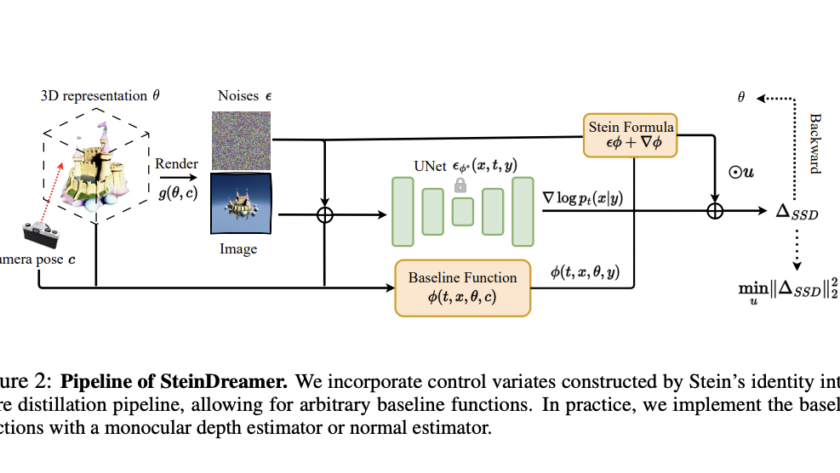
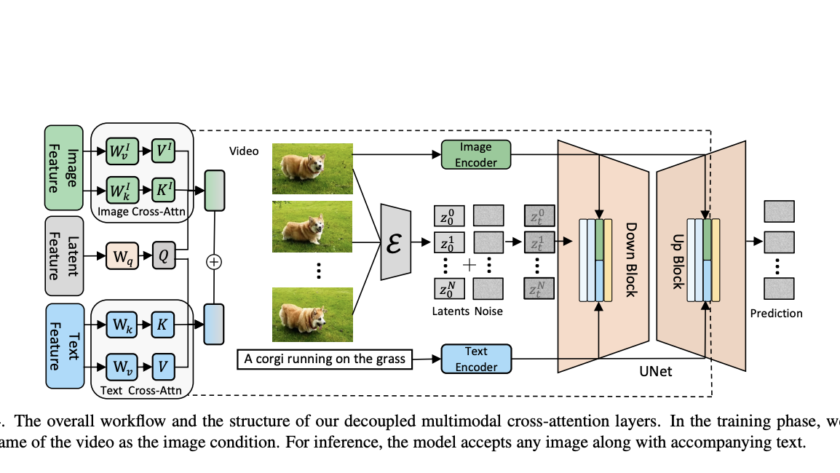
[ad_1]
Text-to-image generation is a unique field where language and visuals converge, creating an interesting intersection in the ever-changing world of AI. This technology converts textual descriptions into corresponding images, merging the complexities of understanding language with the creativity of visual representation. As…