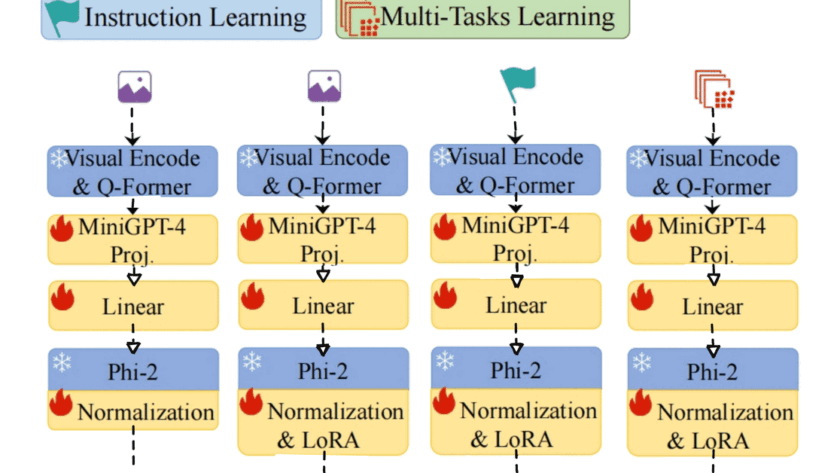
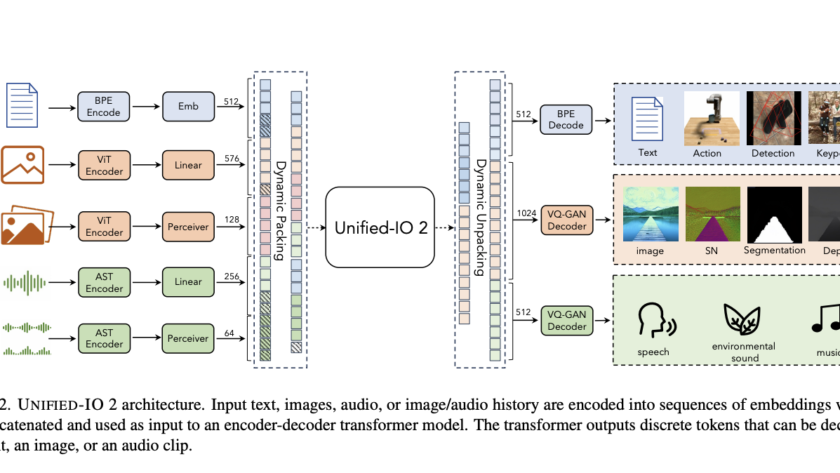
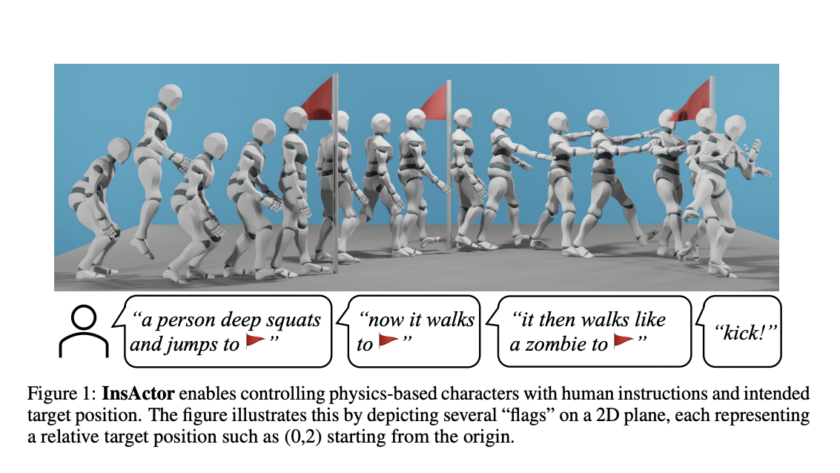
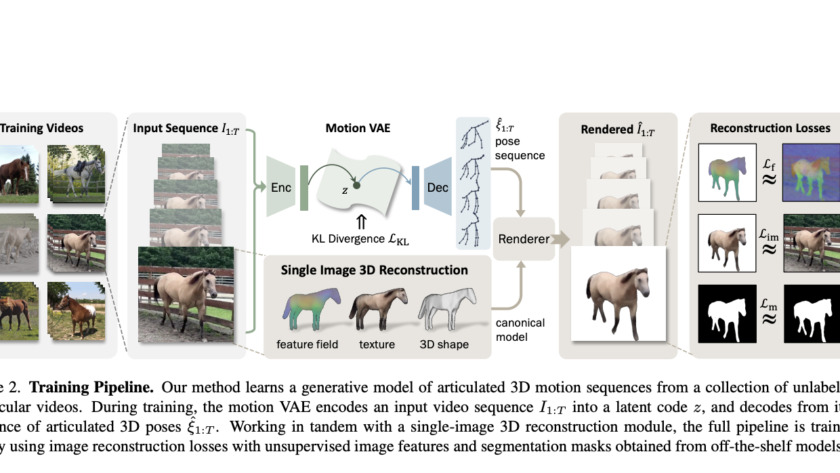
[ad_1]
The development of multimodal large language models (MLLMs) represents a significant leap forward. These advanced systems, which integrate language and visual processing, have broad applications, from image captioning to visible question answering. However, a major challenge has been the high computational resources…