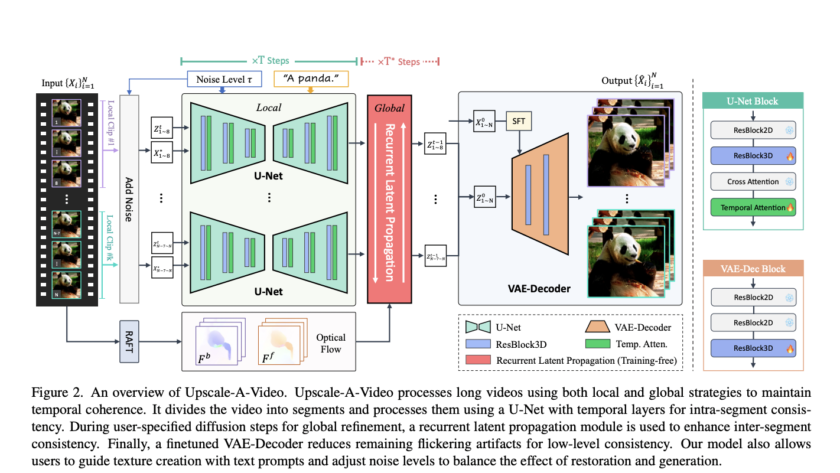
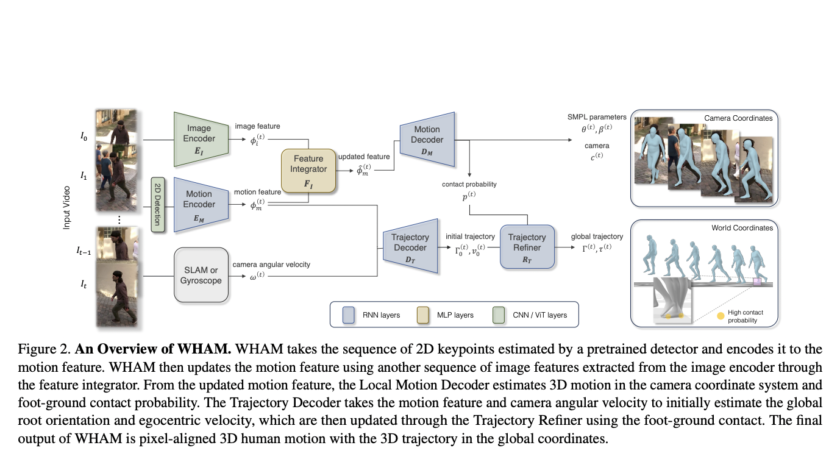
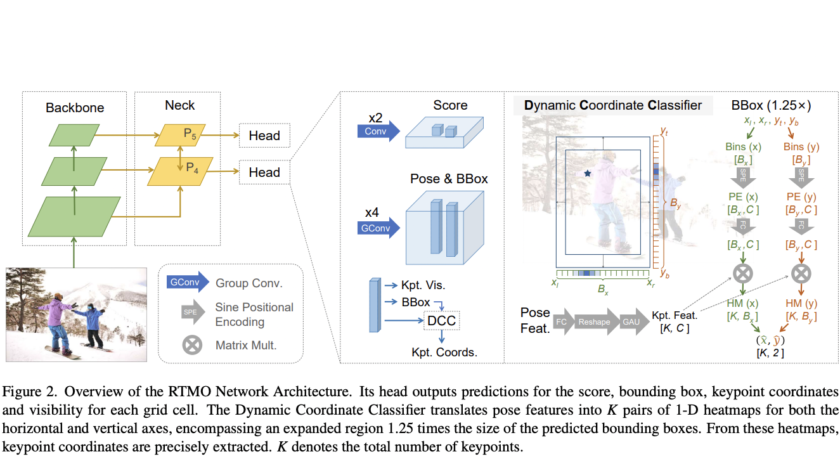
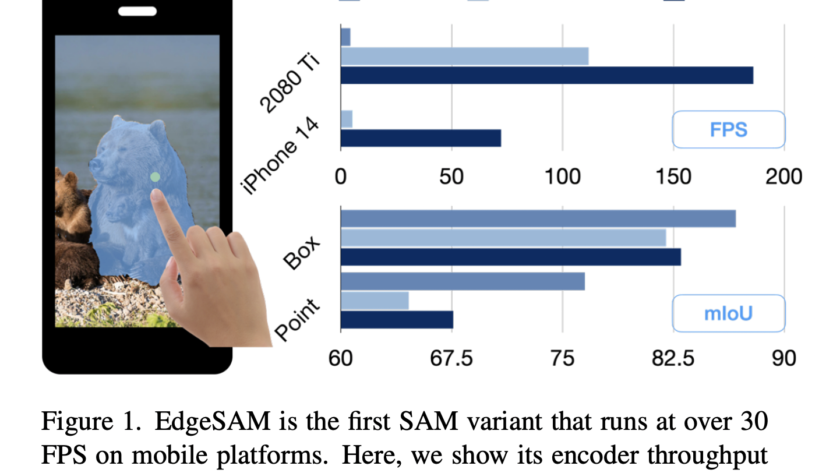
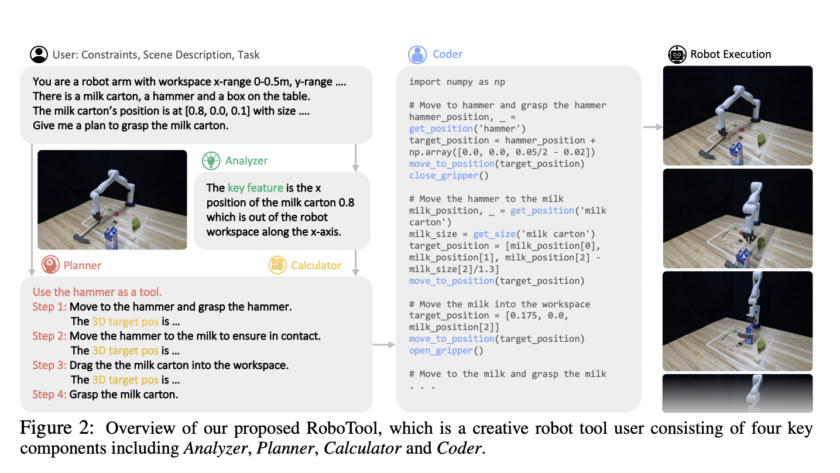
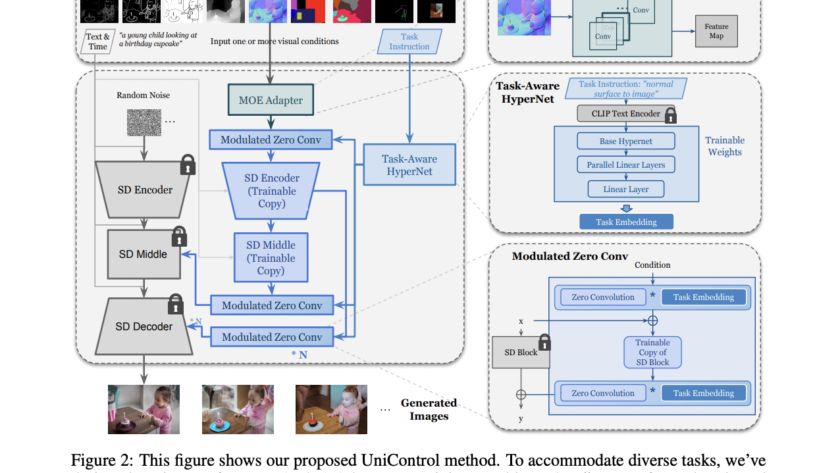
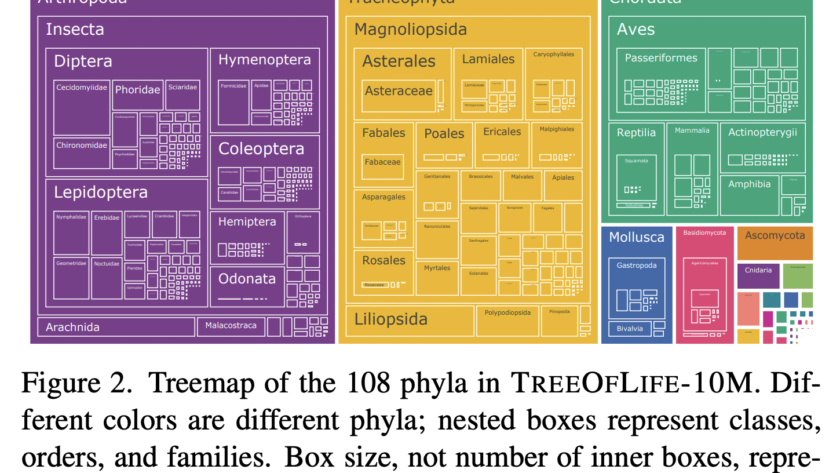
[ad_1]
The progress in neural rendering has brought significant breakthroughs in reconstructing scenes and generating new viewpoints. However, its effectiveness largely depends on the precise pre-computation of camera poses. To minimize this problem, many efforts have been made to train Neural Radiance Fields…