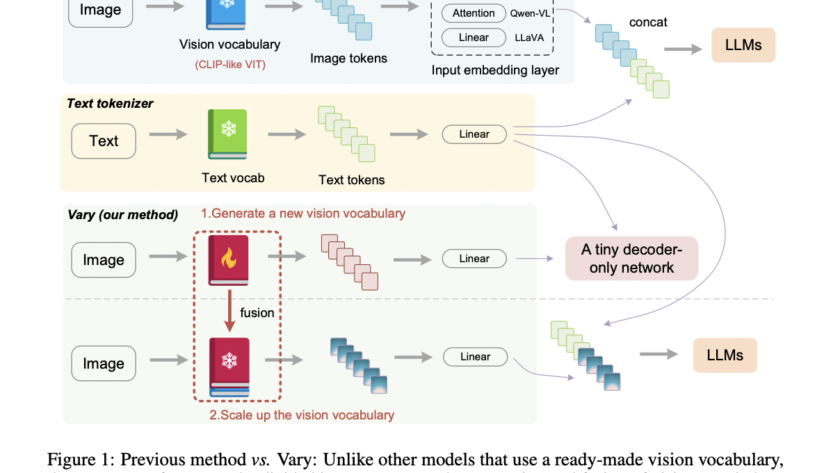
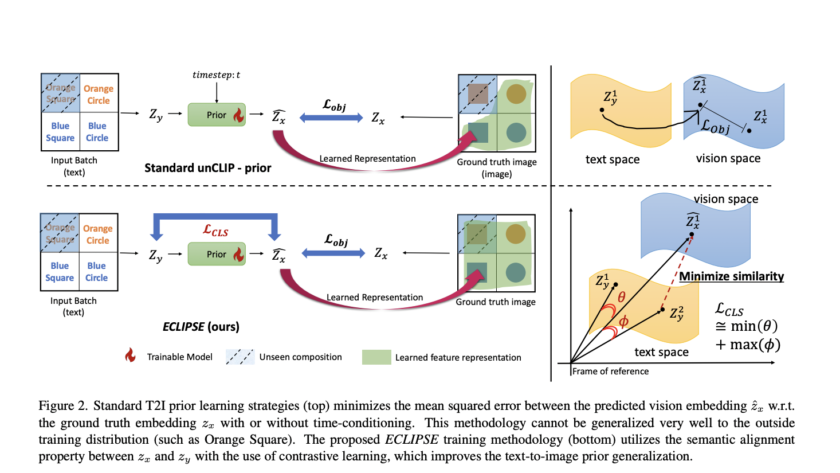
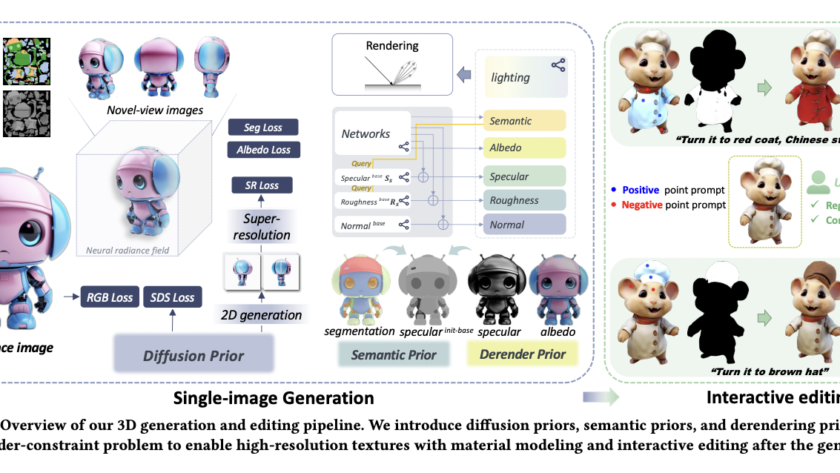
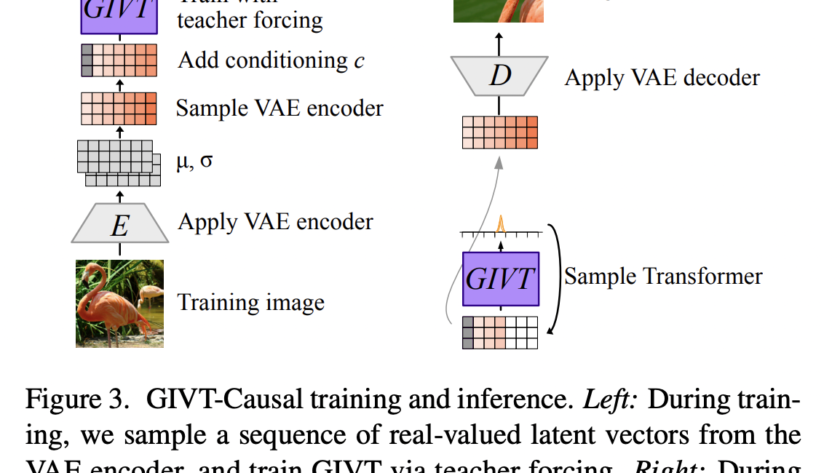
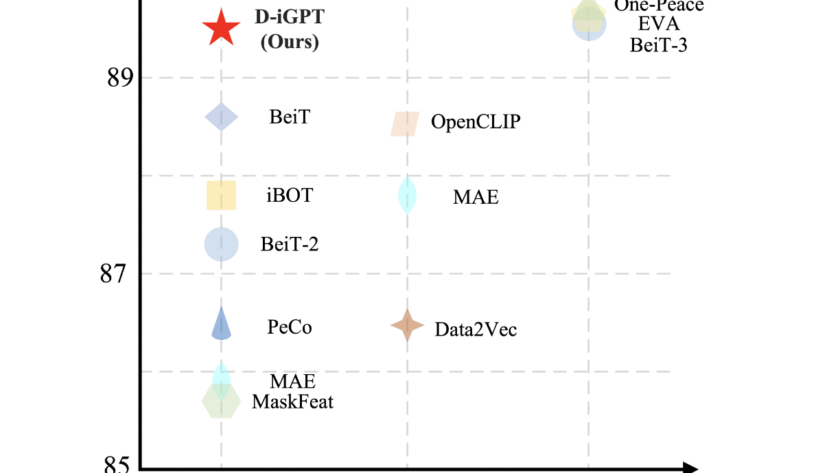
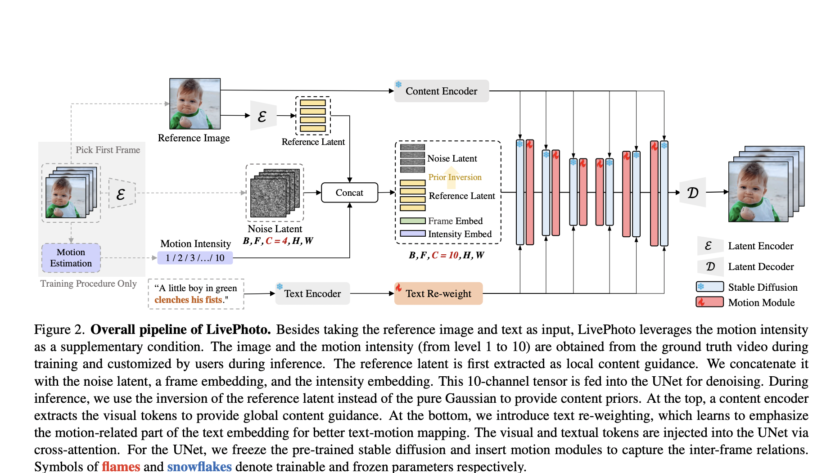
[ad_1]
Large Vision-Language Models (LVLMs) combine computer vision and natural language processing to generate text descriptions of visual content. These models have shown remarkable progress in various applications, including image captioning, visible question answering, and image retrieval. However, despite their impressive performance, LVLMs…