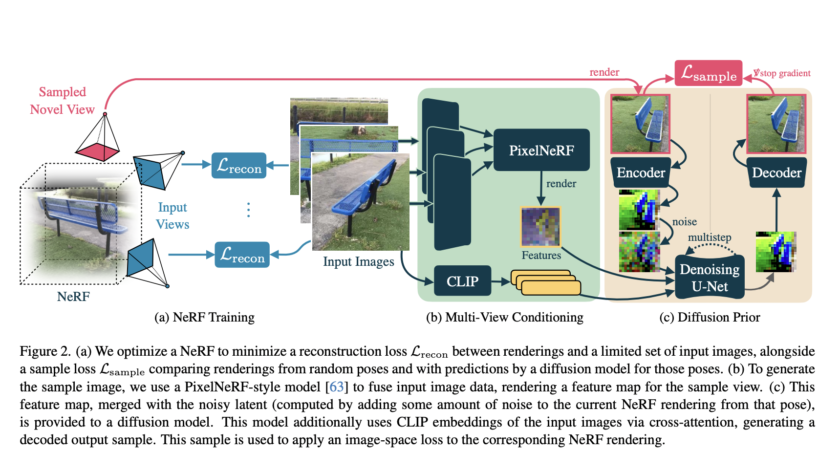
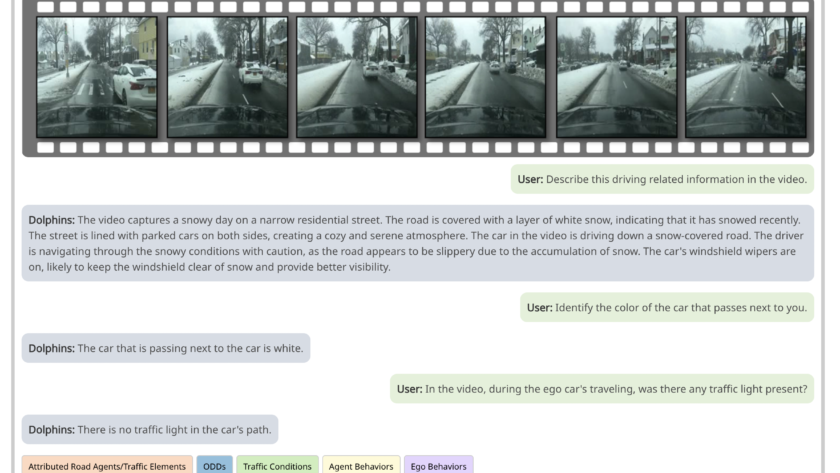
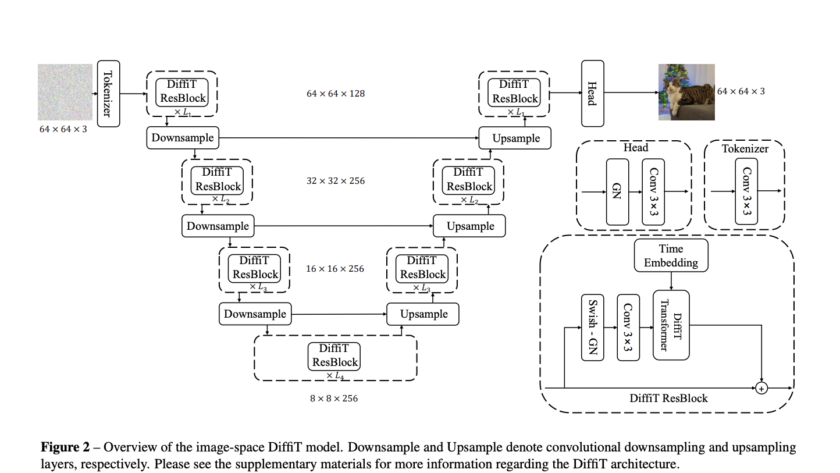
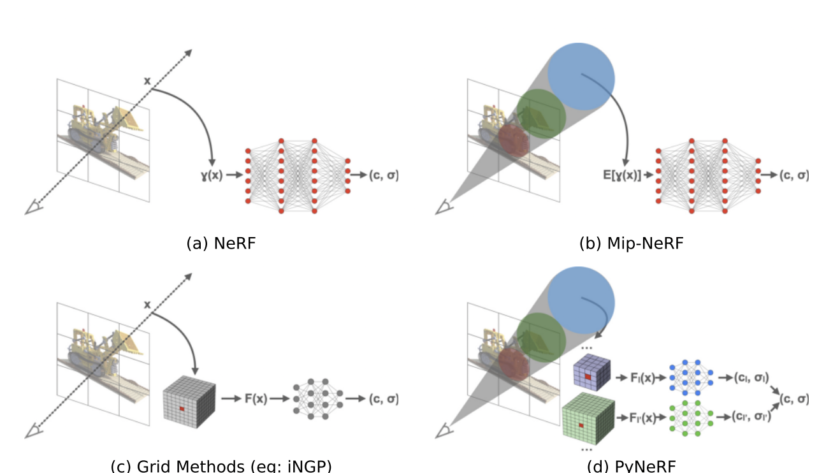
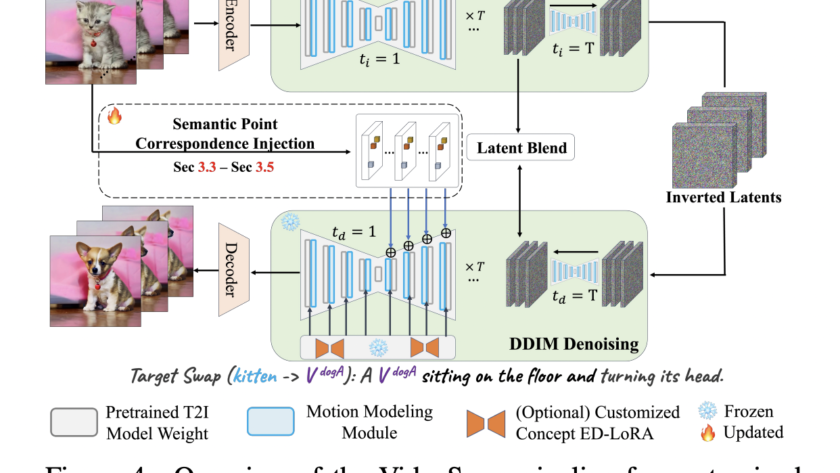
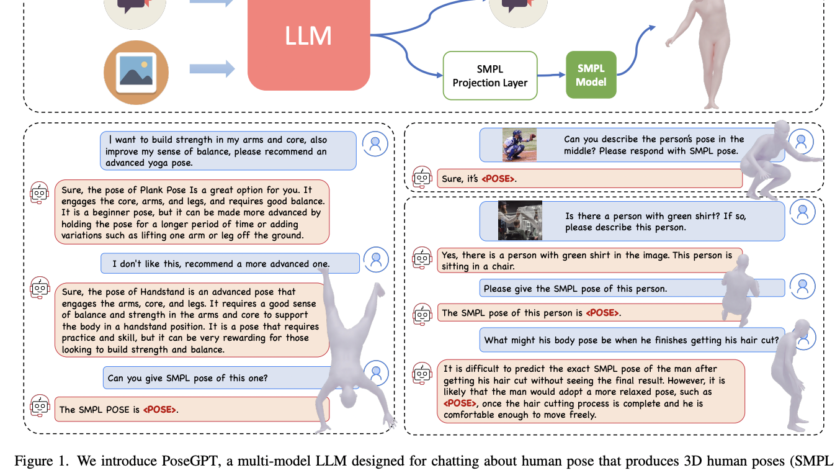
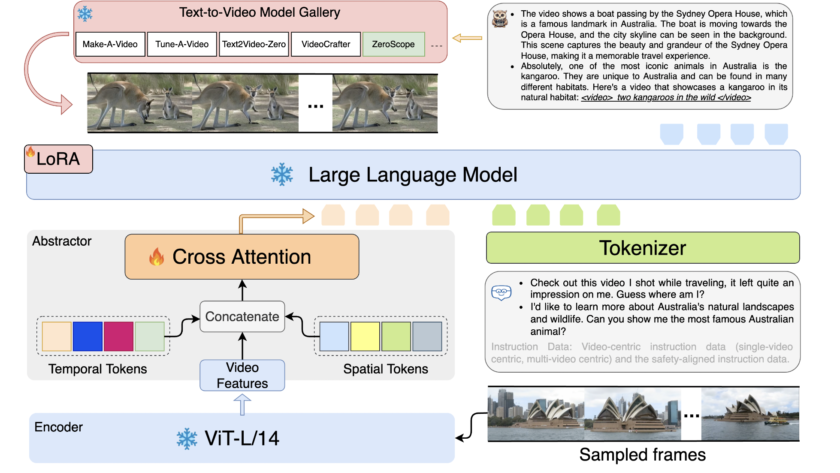
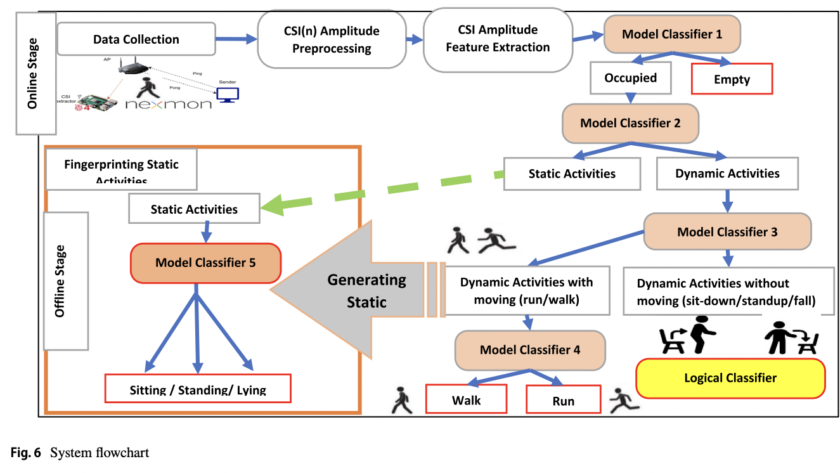
[ad_1]
How can high-quality 3D reconstructions be achieved from a limited number of images? A team of researchers from Columbia University and Google introduced ‘ReconFusion,’ An artificial intelligence method that solves the problem of limited input views when reconstructing 3D scenes from images.…