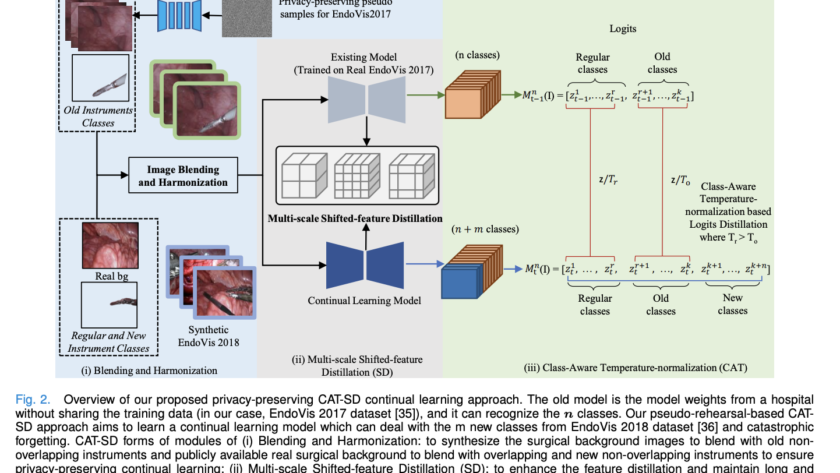
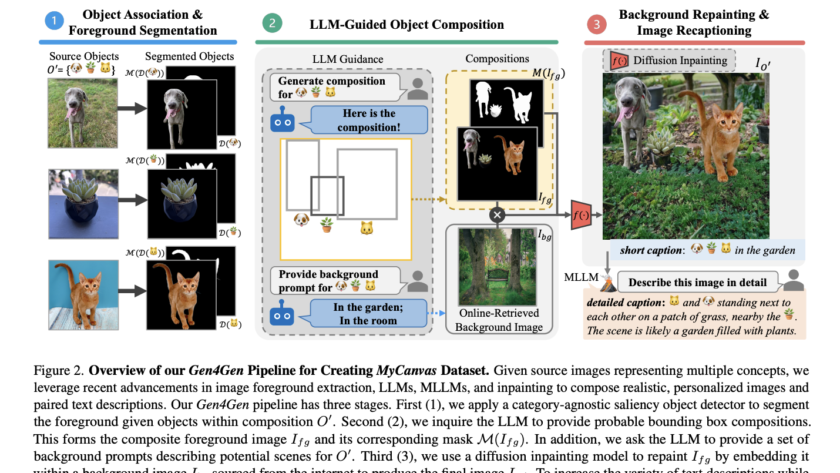
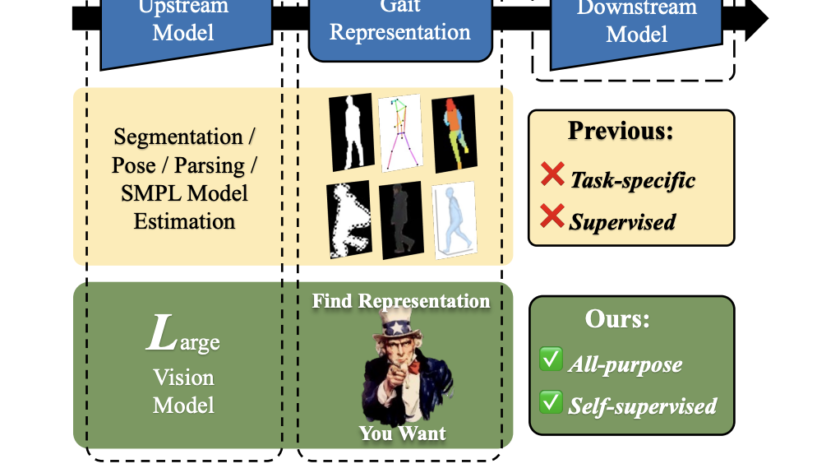
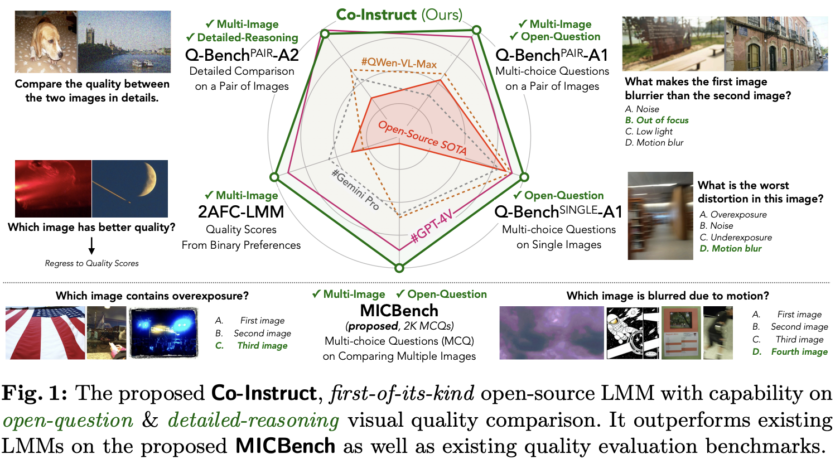
[ad_1]
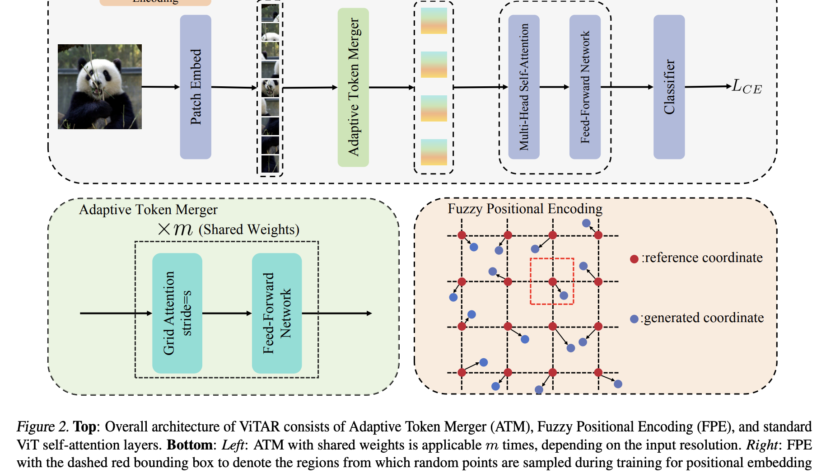
The remarkable strides made by the Transformer architecture in Natural Language Processing (NLP) have ignited a surge of interest within the Computer Vision (CV) community. The Transformer’s adaptation in vision tasks, termed Vision Transformers (ViTs), delineates images into non-overlapping patches, converts each…