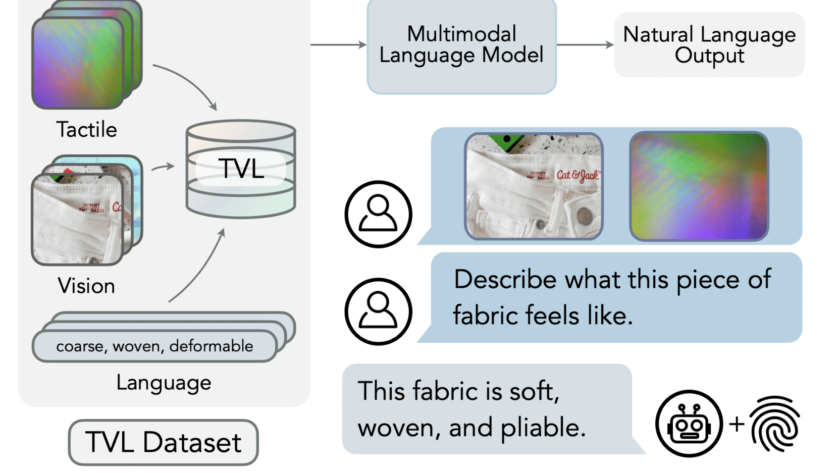
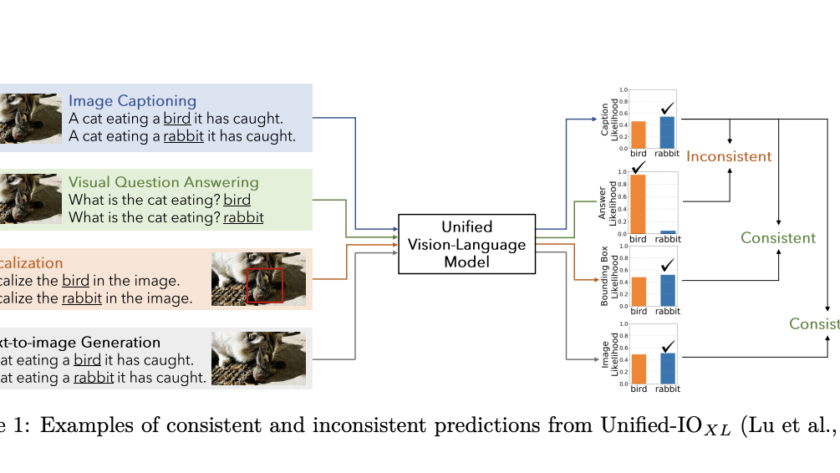
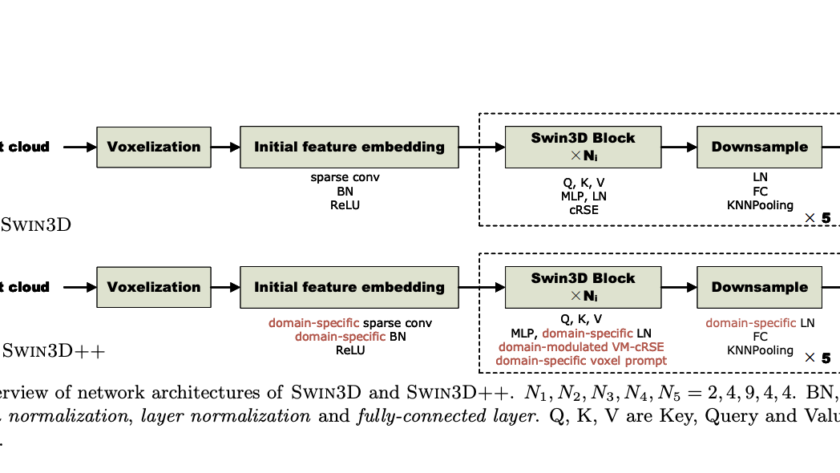
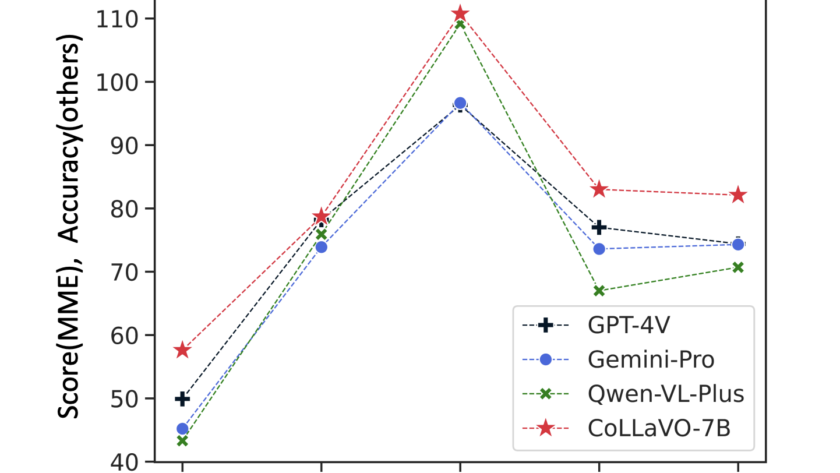
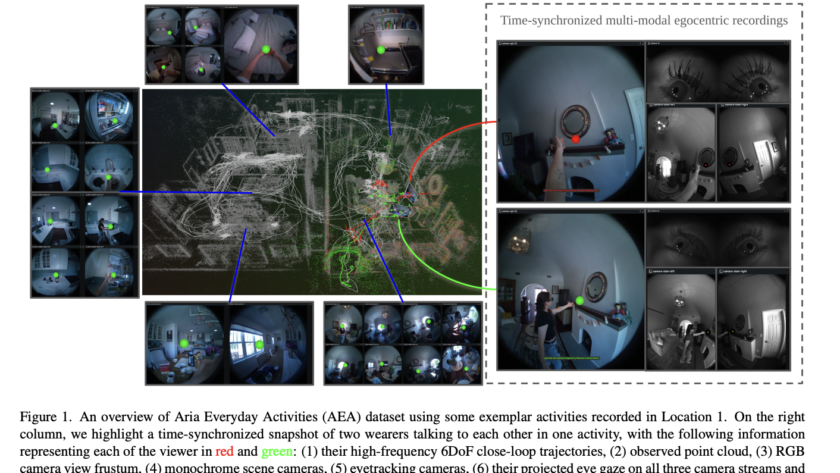
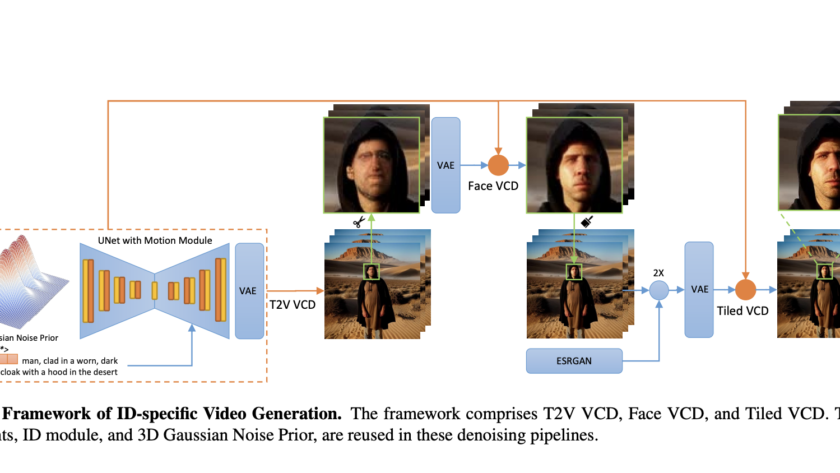
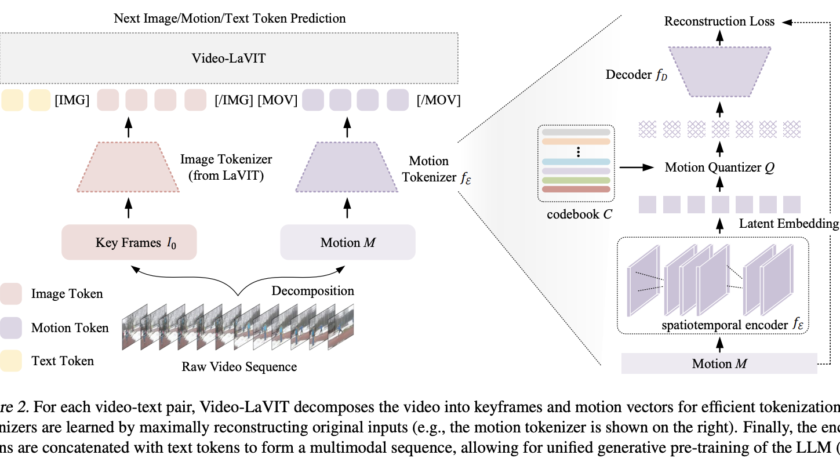
[ad_1]
Almost all forms of biological perception are multimodal by design, allowing agents to integrate and synthesize data from several sources. Linking modalities, including vision, language, audio, temperature, and robot behaviors, have been the focus of recent research in artificial multimodal representation learning.…