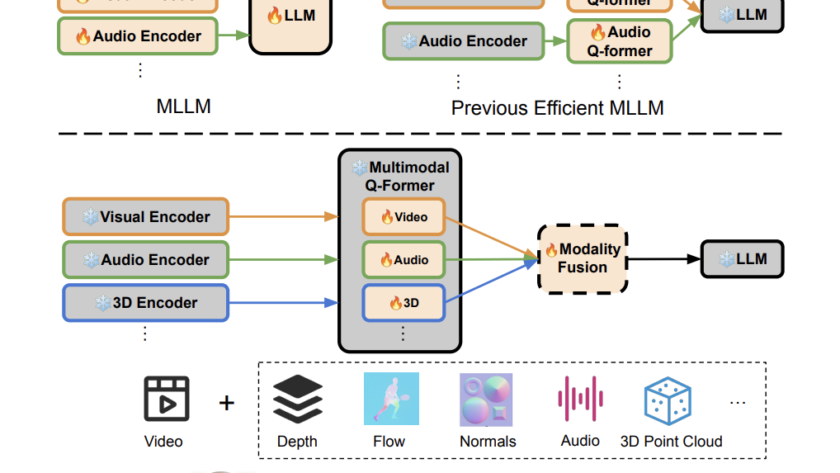
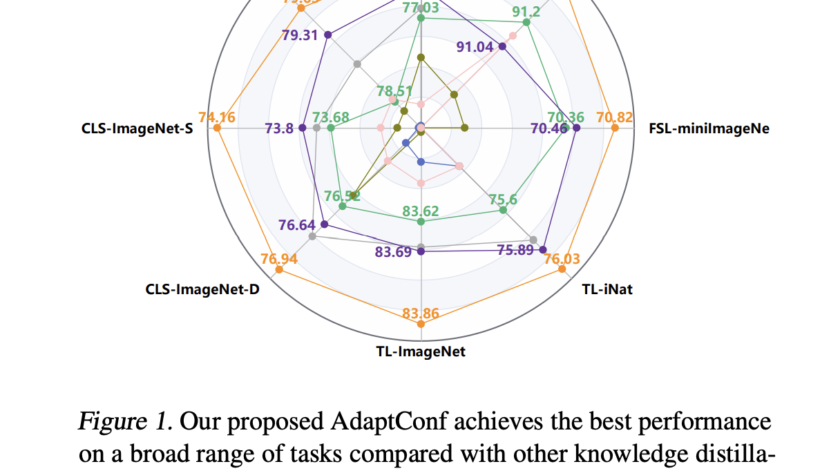
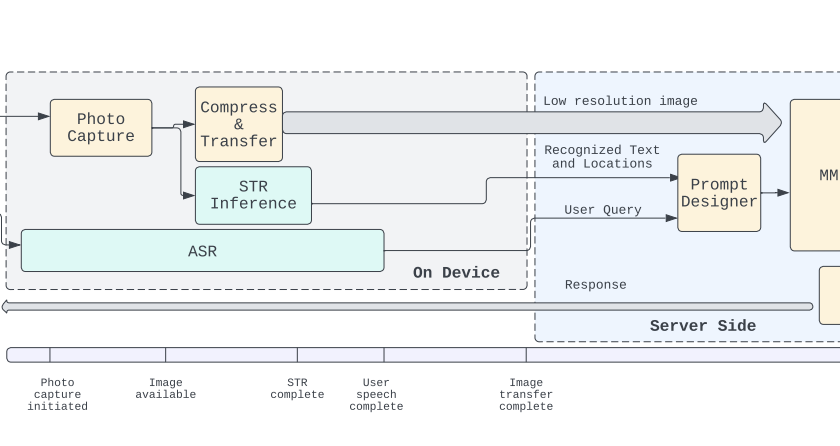
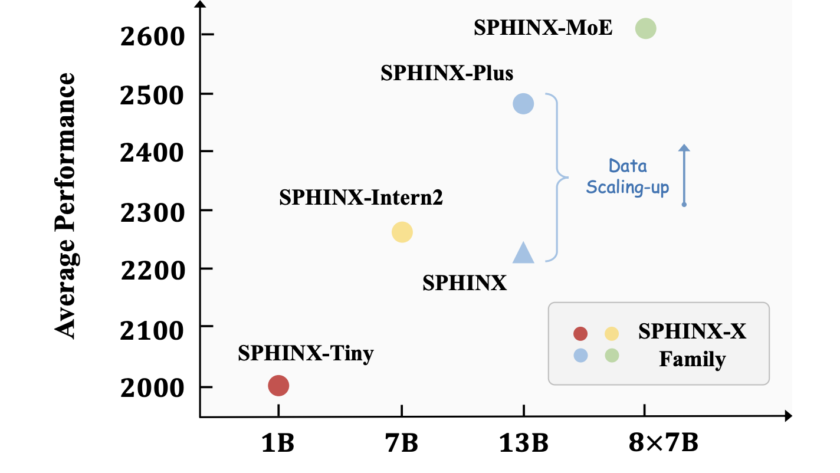
[ad_1]
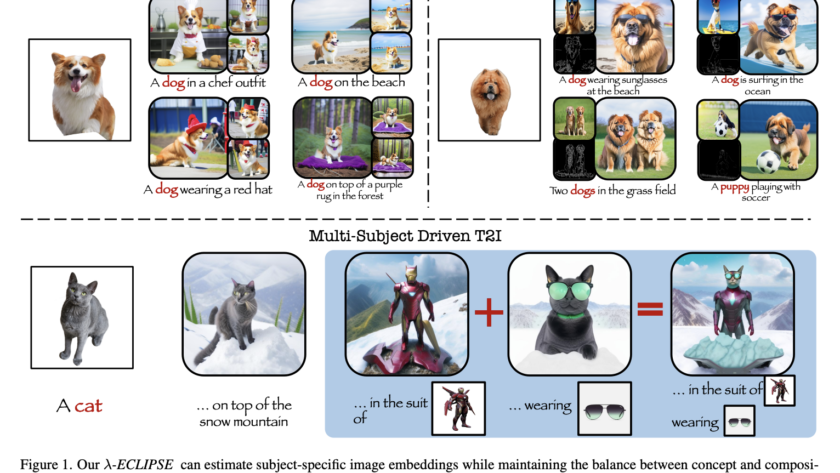
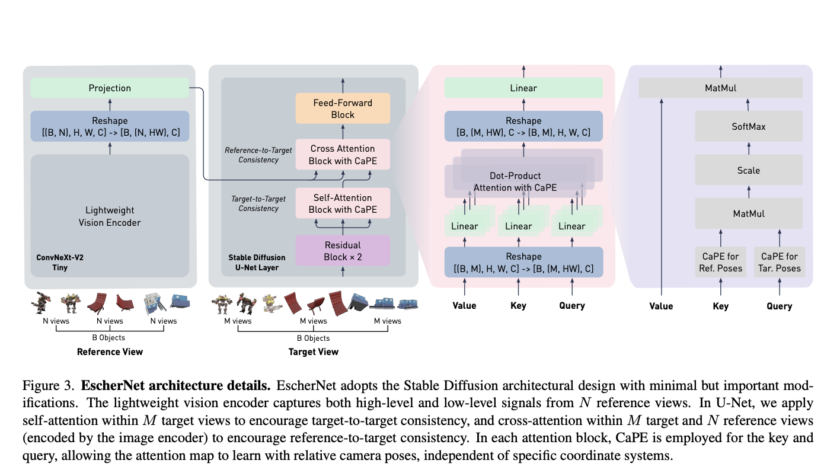
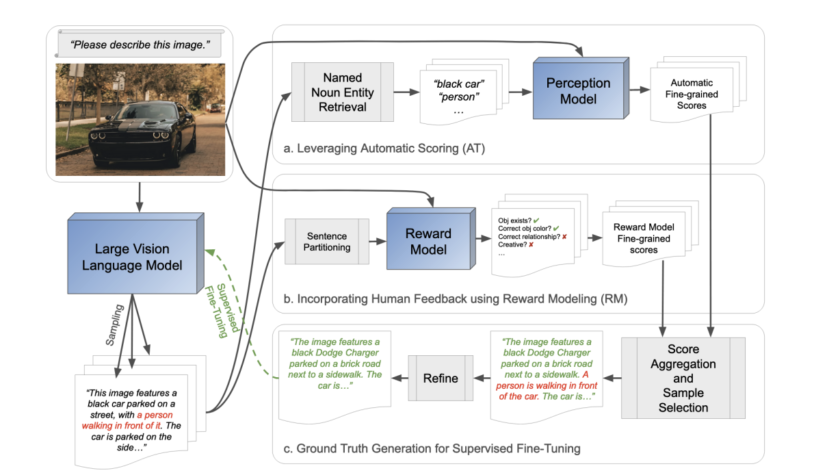
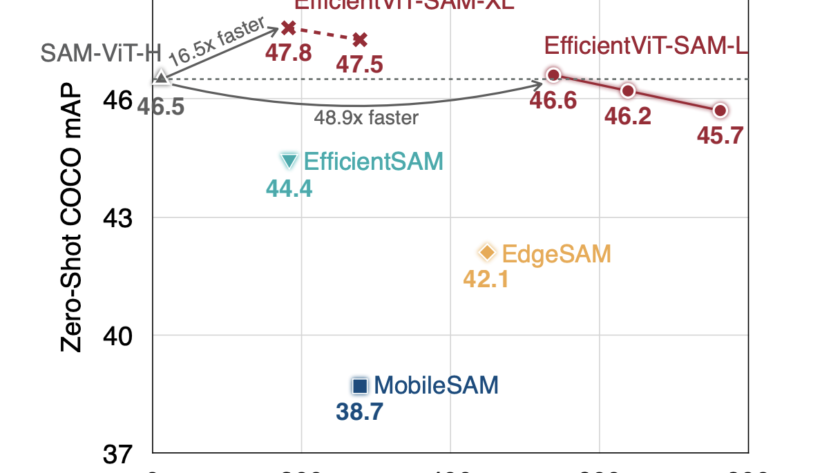
The intersection of artificial intelligence and creativity has witnessed an exceptional breakthrough in the form of text-to-image (T2I) diffusion models. These models, which convert textual descriptions into visually compelling images, have broadened the horizons of digital art, content creation, and more. Yet…