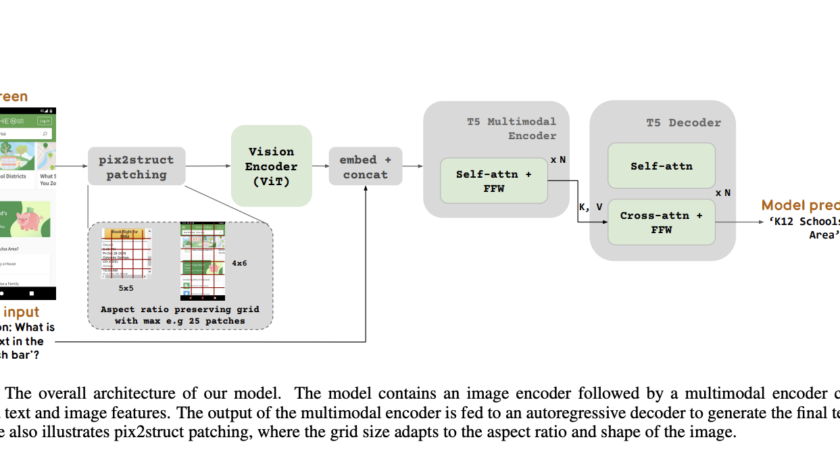
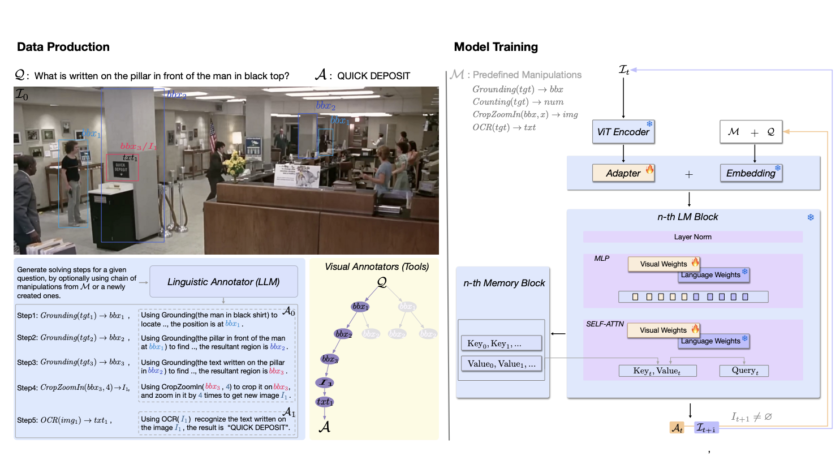
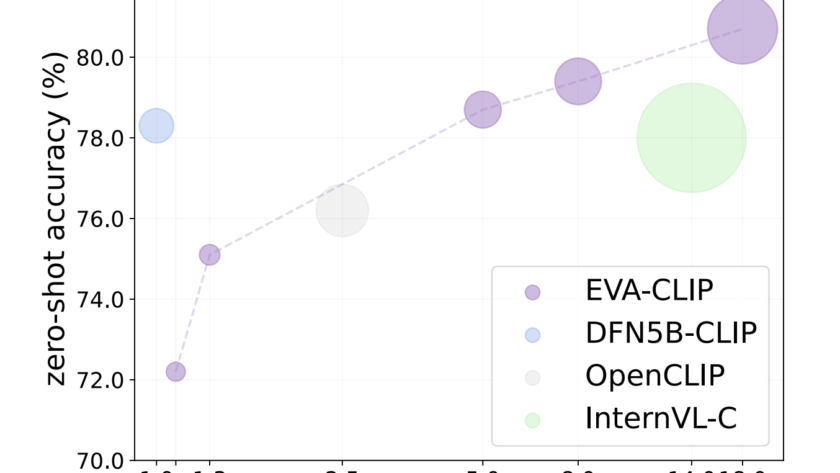
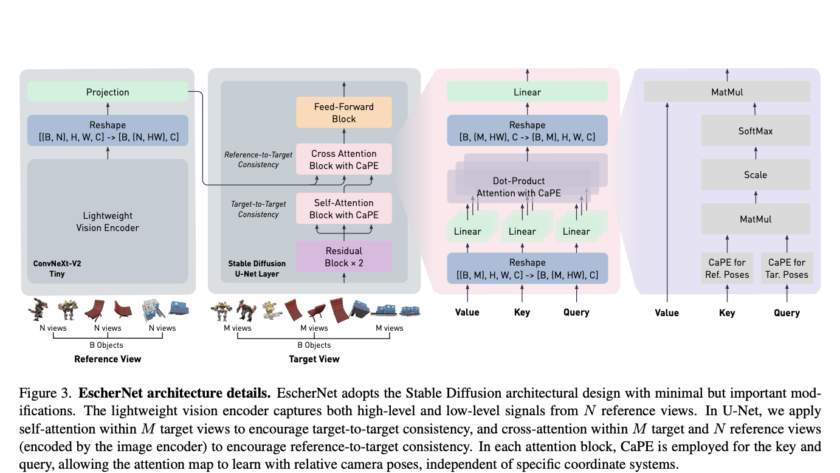
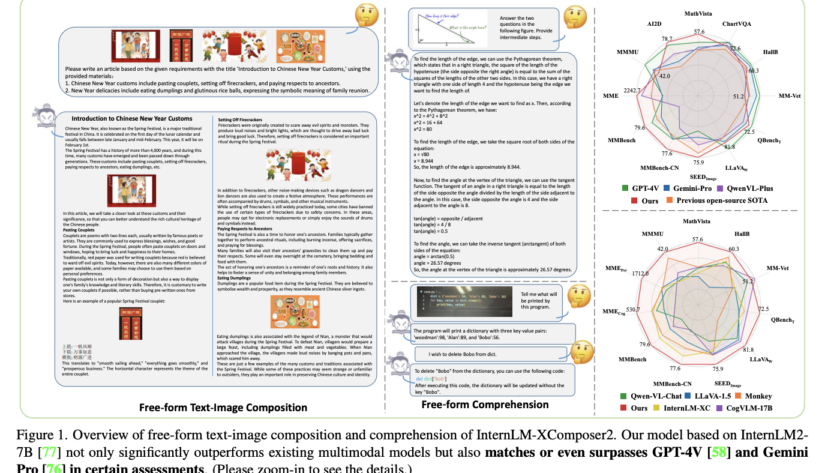
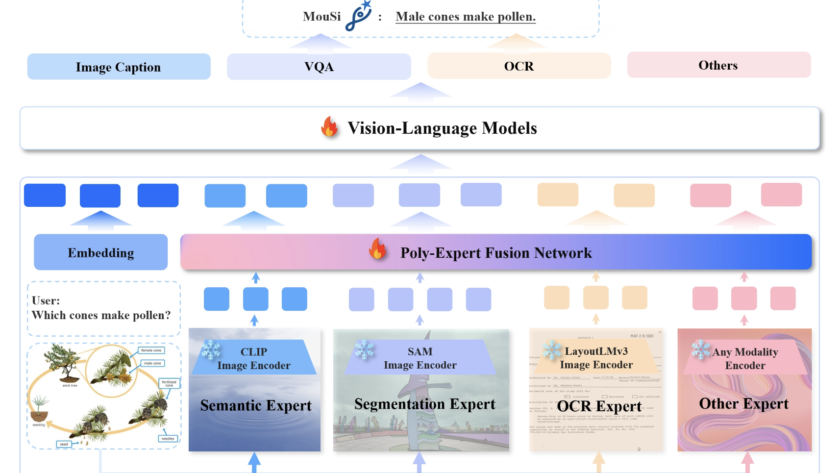
[ad_1]
The capacity of infographics to strategically arrange and use visual signals to clarify complicated concepts has made them essential for efficient communication. Infographics include various visual elements such as charts, diagrams, illustrations, maps, tables, and document layouts. This has been a long-standing…