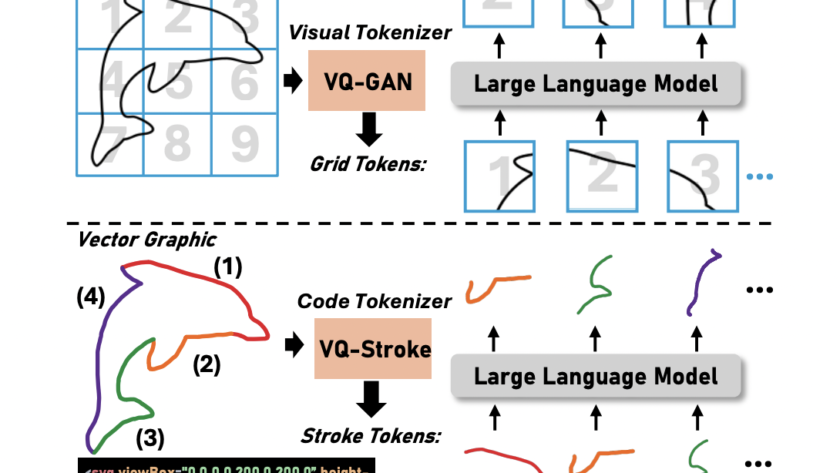
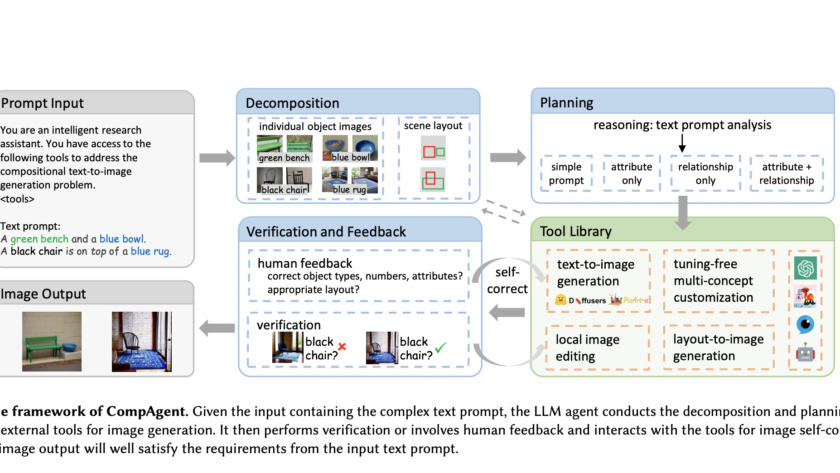
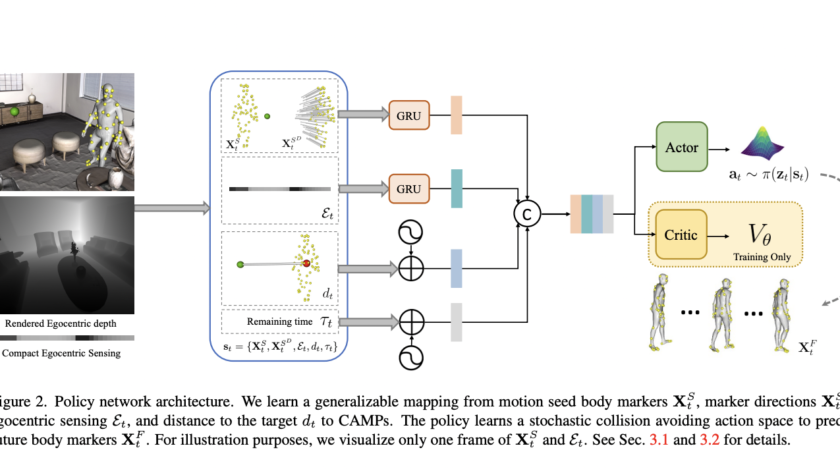
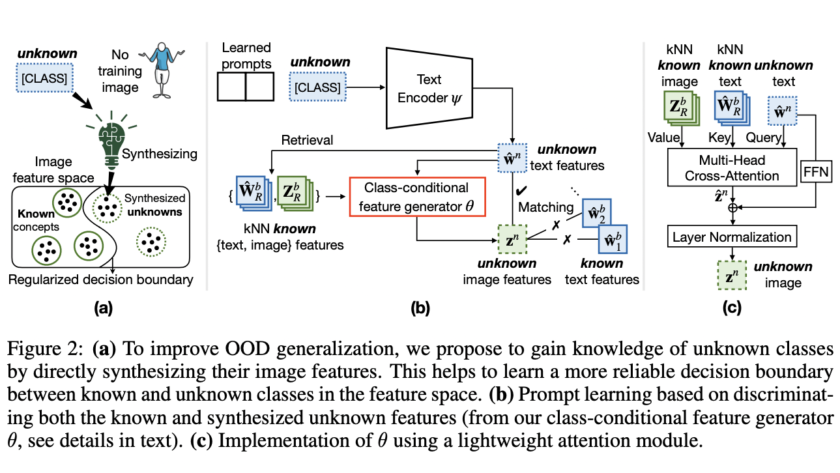
[ad_1]
In the dynamic arena of artificial intelligence, the intersection of visual and linguistic data through large vision-language models (LVLMs) is a pivotal development. LVLMs have revolutionized how machines interpret and understand the world, mirroring human-like perception. Their applications span a vast array…