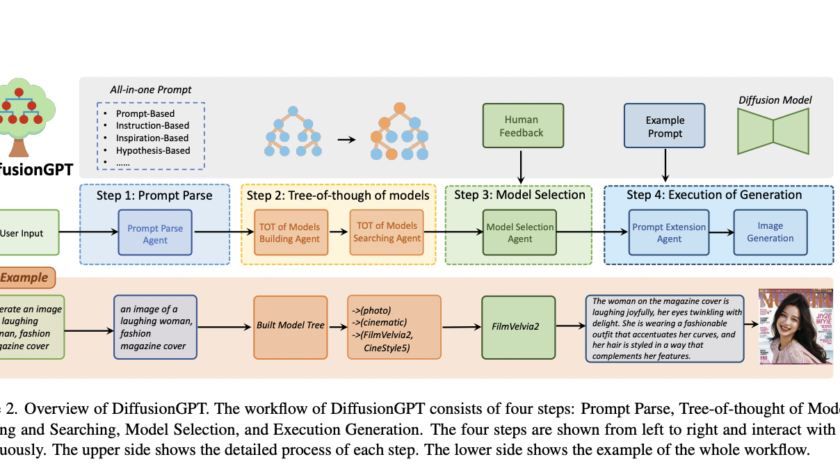
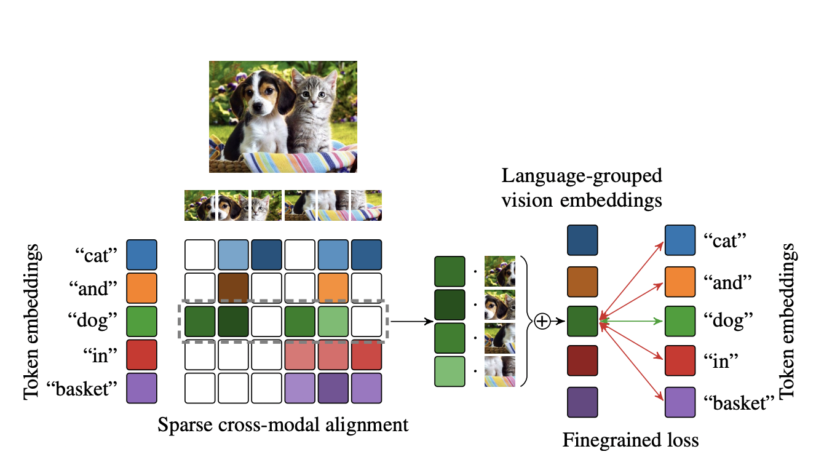
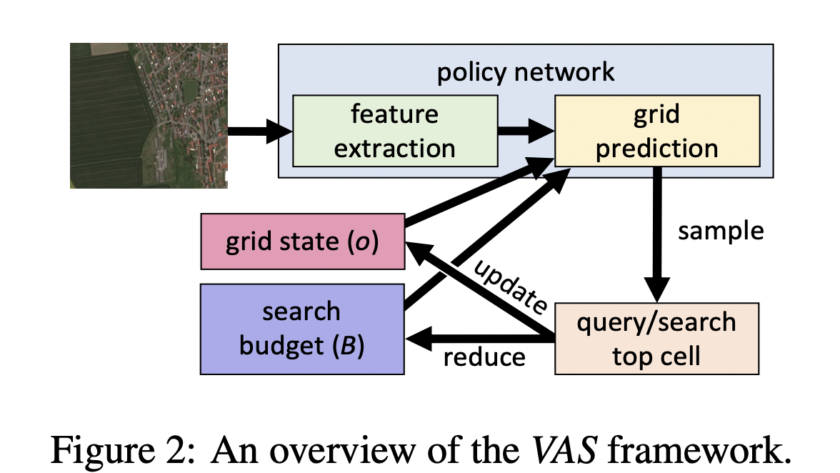
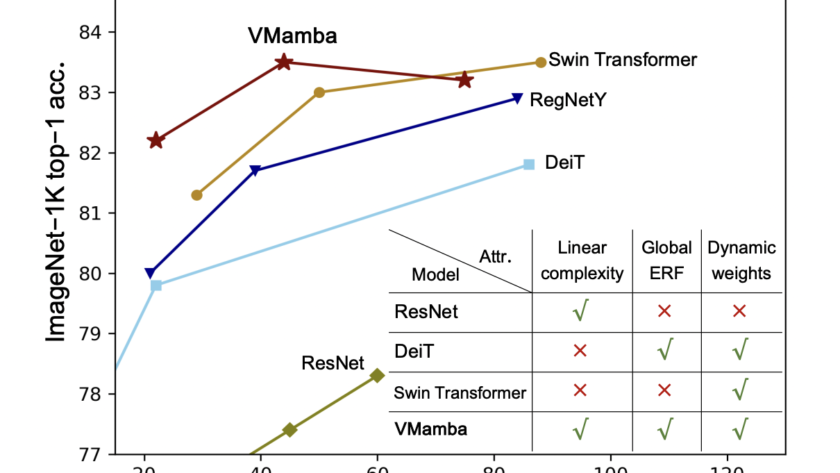
[ad_1]
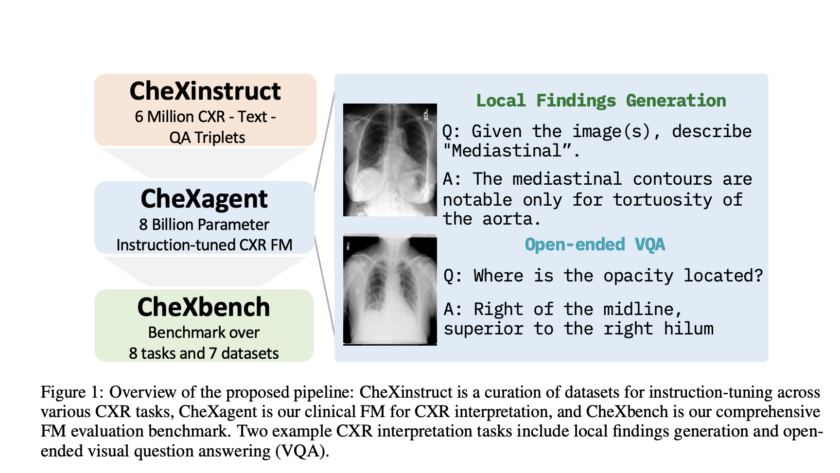
Artificial Intelligence (AI), particularly through deep learning, has revolutionized many fields, including machine translation, natural language understanding, and computer vision. The field of medical imaging, specifically chest X-ray (CXR) interpretation, is no exception. CXRs, the most frequently performed diagnostic imaging tests, hold…